
Automating Conference Scheduling with Genetic Algorithms at CSE23 and Beyond
Scheduling large conferences—such as the 2023 SIAM Conference on Computational Science and Engineering (CSE23), which was held earlier this year in Amsterdam, the Netherlands—is quite difficult. CSE23 took place over the course of five days and consisted of roughly 2,000 presentations in 400 minisymposia across 12 timeslots and 40 rooms of dramatically varying capacity (from 20 to 1,746 people). In the past, conference organizers and SIAM staff have manually assigned presentations to minisymposia and mapped the minisymposia to timeslots and rooms by hand; this is naturally a tedious and error-prone undertaking. However, looking at the task as a mathematical problem makes it much more palatable. This year—and for the first time in SIAM history—the scheduling process for a SIAM conference was automated thanks to Alicia Klinvex (Naval Nuclear Laboratory), who designed the methodology and wrote a set of C++ and Python codes for CSE23. Interested readers can view this code online. Here, we’ll outline the processes and decisions that informed the code’s design and hopefully encourage future conference organizers to adopt a similar methodology.
Scheduling Constraints
Our code had to account for a number of scheduling limitations:
- Speaker Conflict: No speaker or minisymposium organizer can be in two rooms at the same time.
- Room Equipment: Minitutorials and certain minisymposia—like a CSE23 session with live demonstrations on real pool tables—require rooms with special setups.
- Timeslot Suitability: Some speakers and minisymposium organizers are only available during specific timeslots. Because timeslots are not always the same length, longer minisymposia cannot be scheduled in short timeslots.
- Multipart Sequence: Some minisymposia have multiple parts. Part I must come before part II, which must come before part III, and so forth.
- Room Size: More popular minisymposia should take place in larger rooms, thus requiring an automated method to estimate attendance.
- Topic: Minisymposia that address similar topics should be assigned to different timeslots, e.g., all machine learning minisymposia should not take place simultaneously. An automated method to estimate the similarity of two minisymposia is therefore necessary.
- Multipart Adjacency: Multipart minisymposia should ideally occur in the same room during adjacent timeslots.
Metadata Collection
We used the citation counts of recent publications to estimate the prospective attendance (and hence the required room size) of a given lecture. Since some presenters had common/repeated names, we first checked for Google Scholar entries with their names and current affiliations. However, this method is very subjective to nicknames and other name changes; unless presenters explicitly added multiple names to their Google Scholar accounts or included papers that published under a different name, the data may be incorrect. We therefore welcome suggestions for better ways to estimate session attendance — readers can submit their ideas as issues on our GitHub repository.
We applied two different methods to evaluate the likeness between two minisymposia. When testing the code on abstracts from the 2019 SIAM Conference on Computational Science and Engineering, we first utilized Python’s Natural Language Toolkit to measure the abstracts’ similarity, then employed \(k\)-means++ to cluster the data into groups. We assumed that minisymposia in the same group were similar to each other. Later, when working with CSE23 data, each organizer had to pick three “topic codes” that we used to assess similarity.
Generating a “Good Enough” Schedule
Because scheduling is an NP-complete integer programming problem, we are unlikely to find the globally optimal result for our constraints. However, a simple genetic algorithm provides a remarkably good solution. Our approach is as follows:
- Start with a randomly generated population of potential schedules.
- Compute the penalty for each schedule based on the desired characteristics.
- Breed the members of the current population—favoring those with the smallest penalties—to obtain a new population.
- Introduce genetic mutations to the new population.
- Go back to step 2 and repeat.
For our purposes, the first step is clear; we perform random permutations on the set of minisymposia to obtain an initial population of schedules.
To breed two schedules in step 3, we let \(k\) be a random number of timeslots (between 0 and the total number of timeslots), select the first \(k\) timeslots of the first parent schedule, and copy the data to the first \(k\) timeslots of the child schedule. We then generate the remaining data from the second parent while maintaining the property that each minisymposium appears in the schedule only once. We also make easy fixes to satisfy the adjacency criteria for multipart minisymposia and room assignments, which repositions various sessions.
For step 4, we implement genetic mutations by swapping two random minisymposia within a schedule.
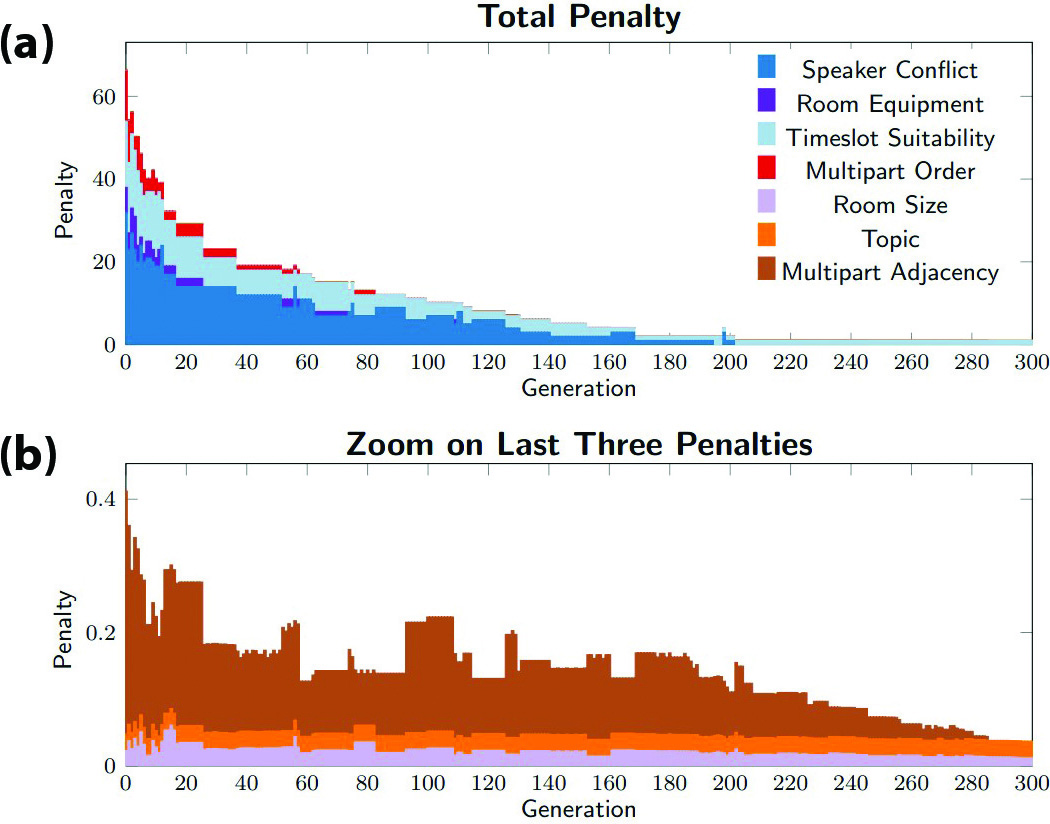
Schedule Penalty Scheme
In order to rank a population, we must define a penalty for each schedule that it contains. Every scheduling consideration contributes to the score. The first four considerations are mandatory and have high penalties for violations of the requirements, while the remaining three considerations fall into the “would be nice” category and incur significantly smaller penalties. We calculate each penalty in a specific way:
- Speaker Conflict: +1 for each pair of minisymposia in the same timeslot that share a common speaker or organizer.
- Room Equipment: +1 for each time a specific room request is not honored.
- Timeslot Suitability: +1 for each time a schedule constraint is not honored.
- Multipart Sequence: +1 for each time a later part of a multipart minisymposium is scheduled before its predecessor.
- Room Size: We sort the rooms based on size from \(r-1\) (largest) to 0 (smallest), where \(r\) is the total number of rooms. Ties are broken arbitrarily. Suppose that there are \(n\) minisymposia; each minisymposium \(i \in \{ 1,2,...,n\}\) has an associated value \(m_i \in \{ 0,1,...,r - 1\}\) that indicates the index of the smallest room to which it can be assigned and a value \(a_i \in \{ 0,1,...,r - 1\}\) that specifies its actual assignment. The penalty is \(\Sigma _{a_i < m_i}({m_i} - {a_i})^2/\Sigma _i m_i^2\), which is always less than 1.
- Topic: We focus on the case with topic codes. Each pair of topics has a pre-assigned similarity of 0 (none), 1 (some), or 2 (identical). Every minisymposium has three topics, so we sum up the similarities across all nine possible pairings of keywords for a value between 0 and 18. The topic penalty is the sum of all similarities between pairs of minisymposia in the same timeslot, divided by the sum of the similarities for all minisymposia. This penalty is also always less than 1.
- Multipart Adjacency: We consider two factors for multipart minisymposia. First, we sum up the number of times that a later part of a multipart minisymposium is not scheduled for the slot that immediately follows its predecessor. Second, we sum up the number of times that a later part of a multipart minisymposium is not scheduled in the same room as its predecessor. We divide this outcome by the number of minisymposia that have a predecessor, meaning that the maximum value of this penalty is 2.
The total penalty for the schedule is simply the sum of these listed components. The speaker conflict, room equipment, timeslot suitability, and sequence penalties are much larger than the room size, topic, and adjacency penalties. In reality, it may be impossible to generate a schedule with zero penalty. For instance, there will always be some overlap in the case of 24 linear algebra minisymposia and 12 available timeslots, and speaker constraints may prevent a multipart minisymposium from occurring in adjacent timeslots.
Many potential variations exist for the aforementioned scheduling structure, but this simple scheme performed well for CSE23.
Software
Our GitHub repository includes the following tools:
- A Python script for data mining the citation counts from Google Scholar’s application programming interface
- A Python script that clusters minisymposia based on their abstracts and returns the most common words for each cluster, so that the user understands approximately what topic the cluster represents
- A C++ code that uses a genetic algorithm to assign contributed lectures to minisymposia
- A C++ code that uses a genetic algorithm to generate a conference schedule
- A Qt graphical user interface that tweaks an existing schedule and alerts users if their changes have made the schedule unfeasible.
Results
To obtain the best possible schedule according to our penalty criteria, we ran our genetic scheduler code overnight on a standard workstation with a population size of 10,000 for 100,000 generations.
Our software minimizes the penalties for the first four constraints within the first 250 generations (see Figure 1). We were able to generate a schedule without any speaker conflicts, where all minisymposia were assigned to rooms with appropriate equipment and all multipart minisymposia occurred in the correct order. However, the minimum penalty for timeslot suitability is 1 because the room equipment requirements ensure that one of the minitutorials will be assigned to a shorter timeslot than the others. The multipart adjacency penalty converges to 0 within the first 300 iterations, meaning that all multipart minisymposia take place in adjacent timeslots in the same room. The small penalties that are associated with the remaining constraints continue to decrease until roughly generation 5,000, after which they stagnate for the remainder of the 100,000 generations.
Performance Portability
Many parts of this algorithm can be performed in parallel. For instance, computation of the penalties, breeding, and mutations are all independent tasks. Since we wrote our C++ code with the Kokkos performance portability library, it can run on any hardware—from a cell phone to a graphics processing unit (GPU)—without modifications to the source code [1]. Using a population size of 10,000, we tested the performance of 250 generations on a laptop with a six-core i7 (ninth generation) central processing unit and an NVIDIA GeForce GTX GPU. Our code scales well and requires very little time to generate a reasonable schedule, even on a laptop (see Figure 2).
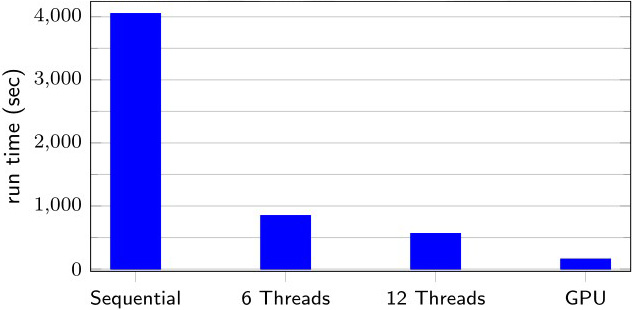
Future Enhancements
Though our algorithm had great success in scheduling CSE23, there is always room for improvement. In the future, we hope to explore several possible enhancements:
- Using natural language processing to determine the similarities between minisymposia based on abstracts
- Minimizing overlap for coauthors
- Using actual room sizes rather than a sized-based ranking of rooms
- Utilizing different metrics to estimate minisymposia attendance
- Collecting actual attendance data from meetings for use in future estimates
- Grouping similar topics in nearby rooms in the conference venue.
Ultimately, however, our genetic scheduler code performs quite well across diverse architectures and automatically optimizes conference schedules. We hope that organizers will use it to schedule other meetings in the future.
Acknowledgments: The authors would like to acknowledge Bob Frost (Naval Nuclear Laboratory) for helpful discussions about the penalty metrics and Karen Devine (Sandia National Laboratories) for constructive feedback about future enhancements.
References
[1] Edwards, H.C., Trott, C.R., & Sunderland, D. (2014). Kokkos. J. Parallel Distrib. Comput., 74(12), 3202-3216.
About the Authors
Alicia Klinvex
Naval Nuclear Laboratory
Alicia Klinvex evaluates future technologies for the Naval Nuclear Laboratory and has a background in high-performance numerical linear algebra. She was a member of the Organizing Committee for the 2023 SIAM Conference on Computational Science and Engineering. Beginning in 2024, Klinvex will serve on the SIAM Membership Committee.

Tamara G. Kolda
Consultant, MathSci.ai
Tamara G. Kolda is a consultant under the auspices of her California-based company, MathSci.ai. She previously worked at Sandia National Laboratories. Kolda specializes in mathematical algorithms and computational methods for data science, especially tensor decompositions and randomized algorithms. She is a SIAM Fellow, co-founded and was editor-in-chief of the SIAM Journal on Mathematics of Data Science, and currently serves as SIAM’s Vice President for Publications and chair of the SIAM Activity Group on Equity, Diversity, and Inclusion.

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
