
Biological Insights in Health AI Improve Efficiency, Efficacy, and Equity
As artificial intelligence (AI) models grow in size and complexity, so does the risk of spurious associations that may yield misleading or even harmful advice [3]. Fortunately, biological data is not random noise — its variance arises from structured, physiologically meaningful processes. If we can model and account for this structure, then variance becomes less of an obstacle and more of a guide. Paradoxically, it is precisely the non-randomness of biology that has introduced persistent biases in AI healthcare models, as most medical models were traditionally trained and validated primarily on data from white, middle-aged men, operating under the assumption that human physiology was roughly Gaussian in a high-dimensional space and so representation shouldn’t matter. But because humans differ systematically across nonrandom modes of variation (see Figures 1a and 1b), ignoring structure has real detrimental costs [4, 6]. Incidentally, we can utilize this same structure to achieve higher precision across all patient groups—even those who are historically underrepresented in medical data—with fewer samples than might otherwise be required.
In a sense, AI models of health-related data are appropriate counterparts to biology itself; both are high-dimensional, nonlinear, and complex in that they can generate unpredictable outcomes. However, the complexity of AI and the complexity of biology do not necessarily align — and when it comes to healthcare, misalignments mean potential for harm. Instead of attempting to correct these mismatches by averaging the data with increasingly large sample sizes, we can more effectively reduce global variance by recognizing and separating data modes whenever possible. Conceptually, doing so reframes biometrics as multimodal distributions rather than single heterogeneous clouds, thereby improving a model’s fit and interpretability with appropriate clustering around intrinsic modes.
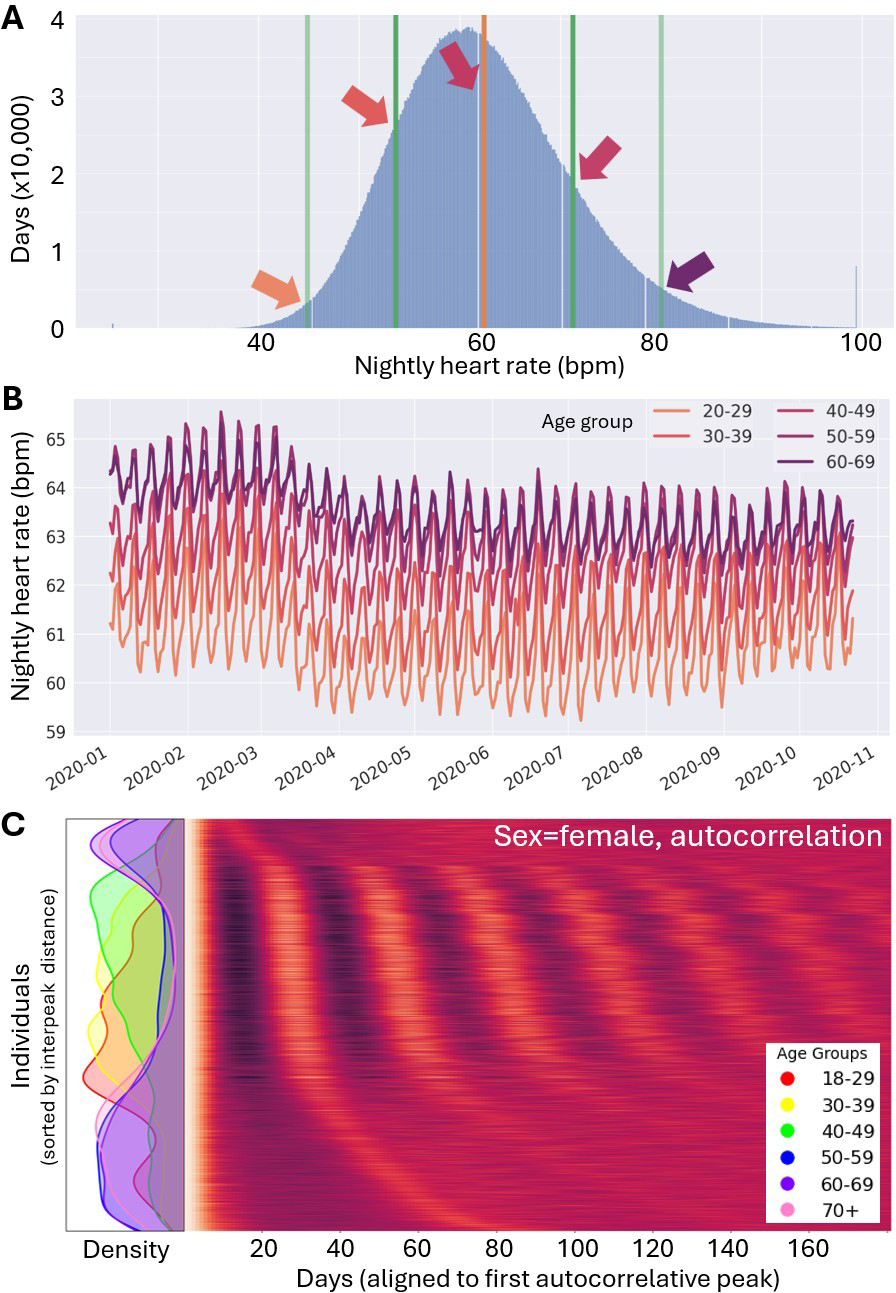
Historically, the field of medicine has implemented this strategy in broad strokes via demographic categories like age, sex, and race — coarse but sometimes useful stratifications when data were scarce and statistics were calculated with pen and paper. Today, however, the widespread use of wearable products (e.g., fitness trackers) and Personal Internet of Things devices provide continuous, high-resolution physiological data streams. This transition from a data-impoverished to data-rich environment in biomedicine allows us to move beyond static demographic bins and toward finer-grained, dynamic physiotypes: parametrizations of individual state and variance structure that we infer directly from data [7]. Such vast amounts of data enable the augmentation, enrichment, and occasional replacement of older systems—like traditional demographic categories—with physiotypes. Because biomedicine is going from data poor to data rich, its associated mathematical modeling techniques deserve a serious glow-up.
Improving Practice By Accounting for Variance Over Time
Throughout history, scientists used the menstrual cycle as a justification for the exclusion of women as research subjects [10]. The assumption was that men and women both have “normal” (i.e., daily) sleep and circadian variance, but the addition of women’s menstrual cycles would increase female variance and stymie a study’s statistics. However, longitudinal and direct measurements do not support this assumption [5, 8]. We found that variance by day in both physiological and behavioral data typically exceeds variance across menstrual cycles — usually by a wide margin. Moreover, cyclicity itself is detectable from label-free data via changes to daily profiles.
By leveraging these findings in a real-world data set that encompasses tens of thousands of people, we found that “sex” is an insufficient label when estimating an individual’s variance (and in the context of historical arguments for exclusion, their merit for inclusion in a study) (see Figure 1c). Instead, the combination of “sex,” “cyclicity,” and the parameters of each time scale of periodicity allowed for the best reduction in residual variance; for our purpose, we considered days, weeks (a social cycle that school and work schedules impose on physiology), menstrual cycles, and age (phase of an individual’s life cycle) (see Figure 1b). Ultimately, our efforts reduced unexplained variability most strongly for older women (who had the lowest residual variance), followed by cyclic women; men often exhibited the highest residual variance once we accounted for temporal structures. Note that this result means that the data reveal the opposite of what has been a historical fear that still causes exclusion and harm. Embracing data in this way lets us dispel so-called boogiemen who have haunted medicine for decades but have remained shadowy and difficult to examine in a straightforward manner.
Conclusions: A Positive Prognosis for Health AI
Two key insights support a positive prognosis for current biases in healthcare-related AI. First, there is no need to exclude any population group from research. Instead, augmenting static demographic labels with data-derived physiotype parameters enables meaningful stratification so that we can fit algorithms to the correct physiotype without inflating model complexity. Second, we should not treat physiotypes as static. Human physiology is nonstationary, and useful information is embedded in the way in which physiotypes evolve over time. Tracking transitions in physiotype clusters improves the detection of emerging conditions [1, 9], and measures like multiscale entropy of signals can forecast future health trajectories. For example, the incorporation of entropy dynamics significantly improved prediction of next week’s glucose regulation in patients with diabetes [2].
Health AI can only accelerate when scientists and practitioners place their faith in the use of biological domain expertise, rather than only in analytic scale. No amount of brute force modeling or data collection can make biological systems efficiently yield their information; instead, learning to appreciate the structure of biology through time yields significant information from variance. By embracing multimodality, temporality, and dynamic physiotypes, we can more closely align the complexity of algorithmic models with the complexity of biology — reducing bias, increasing precision, and ultimately building fairer, more reliable health technologies.
Benjamin Smarr delivered a minisymposium presentation on this research at the 2025 SIAM Conference on Applications of Dynamical Systems, which took place in Denver, Colo., this past May.
References
[1] Barmak, O., Krak, I., Yakovlev, S., Manziuk, E., Radiuk, P., & Kuznetsov, V. (2024). Toward explainable deep learning in healthcare through transition matrix and user-friendly features. Front. Artif. Intell., 7, 1482141.
[2] Burks, J.H., Joe, L., Kanjaria, K., Monsivais, C., O’Laughlin, K., & Smarr, B.L. (2025). Chronobiologically-informed features from CGM data provide unique information for XGBoost prediction of longer-term glycemic dysregulation in 8,000 individuals with type-2 diabetes. PLOS Digit. Health, 4(4), e0000815.
[3] Hasanzadeh, F., Josephson, C.B., Waters, G., Adedinsewo, D., Azizi, Z., & White, J.A. (2025). Bias recognition and mitigation strategies in artificial intelligence healthcare applications. NPJ Digit. Med., 8(1), 154.
[4] James, T.A. (2024, September 24). Confronting the mirror: Reflecting on our biases through AI in health care. Harvard Medical School. Retrieved from https://learn.hms.harvard.edu/insights/all-insights/confronting-mirror-reflecting-our-biases-through-ai-health-care.
[5] Jang, D., Zhang, J., & Elfenbein, H.A. (2025). Menstrual cycle effects on cognitive performance: A meta-analysis. PLoS One, 20(3), e0318576.
[6] Joseph, J. (2025). Algorithmic bias in public health AI: A silent threat to equity in low-resource settings. Front. Public Health, 13, 1643180.
[7] Smarr, B.L. (2024). AI for precision medicine must keep non-random complexity in mind to support equity in outcomes. In 2024 IEEE 20th international conference on e-Science (e-science). Osaka, Japan: IEEE Computer Society.
[8] Varner, K.J., Bruce, L.K., Soltani, S., Hartogensis, W., Dilchert, S., Hecht, F.M., … Smarr, B.L. (2025). Sex differences in the variability of physical activity measurements across multiple timescales recorded by a wearable device: Observational retrospective cohort study. J. Med. Internet Res., 27, e66231.
[9] Viswanath, V.K., Hartogensis, W., Dilchert, S., Pandya, L., Hecht, F.M., Mason, A.E., … Smarr, B.L. (2024). Five million nights: Temporal dynamics in human sleep phenotypes. NPJ. Digit. Med., 7(1), 150.
[10] Zucker, I., & Beery, A.K. (2010). Males still dominate animal studies. Nature, 465(7299), 690.
About the Author
Benjamin L. Smarr
Associate professor, University of California, San Diego
Benjamin L. Smarr is an associate professor of bioengineering and data science at the University of California, San Diego (USCD). His insights from neuroendocrinology and chronobiology allow him to work at the intersection of novel human data sources and artificial intelligences (AIs) to bring physiological insights into real-world settings for large populations. Smarr’s laboratory and collaborations at UCSD encompass community engagement and the debiasing of health AI, with a particular focus on women's health and aging.

Related Reading

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
