
Data-driven Surrogate Model Improves Storm Surge Prediction
Storm surge—an abnormal rise in sea level due to hurricane and typhoon activity in the ocean—is a coastal hazard that poses significant risk to populations and infrastructure (see Figure 1). Factors such as wind speed, tidal patterns, atmospheric pressure, and depth and orientation of the effected water body all contribute to the severity of the surge. Although coastal regions throughout the world experience this dangerous phenomenon, most storm surge studies focus on the U.S. because of its robust data. During the 2025 SIAM Conference on Computational Science and Engineering, which is currently taking place in Fort Worth, Texas, Jinpai (Max) Zhao of the University of Texas at Austin used a surrogate modeling framework to generalize global storm surge and accurately predict water elevation.

While high-fidelity physics-based models generate accurate predictions of storm surges, their computational expense make them better suited for operational forecasting and large-scale risk assessment, rather than real-time use. To circumvent this complication, Zhao and his colleagues are developing data-driven surrogate models that offer similar predictive power at a significantly lower computational cost. Such models utilize techniques like machine learning to make near-instant predictions based on observational or simulated data.
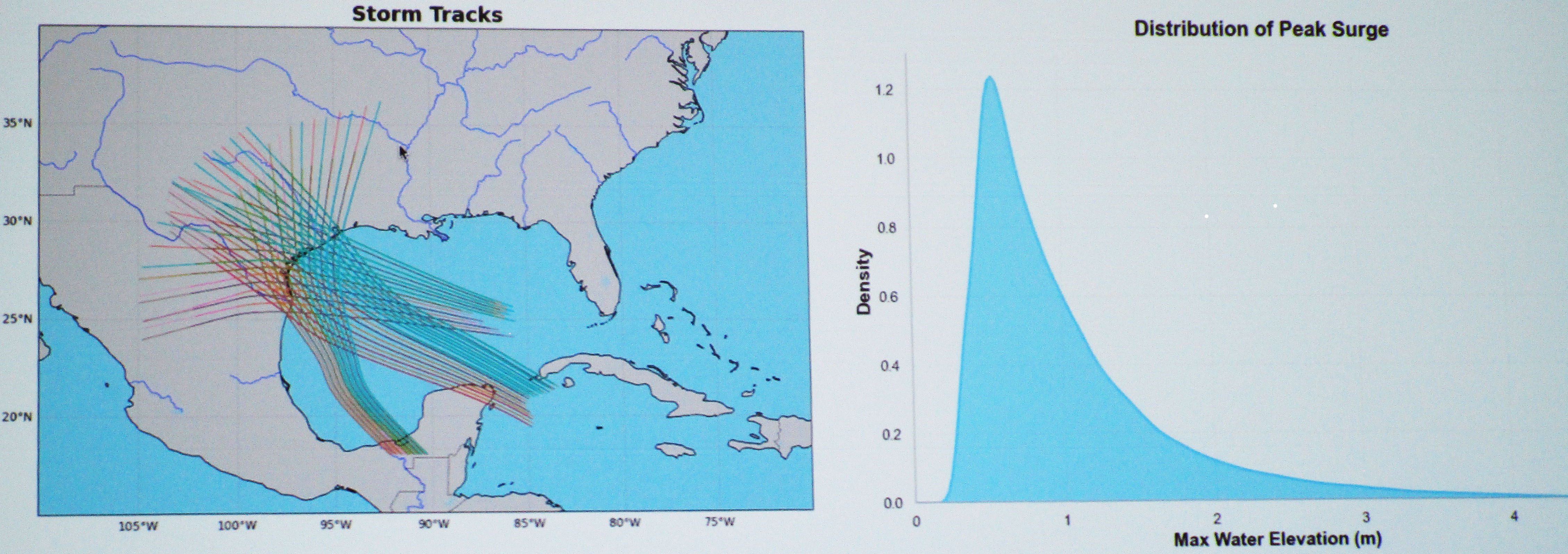
Zhao centers his study on storm surge activity off the coast of Texas in the North Atlantic basin. “Texas storms are special,” he said, citing elements such as extremely high wind pressure and unique surge distributions (see Figure 2). Observational data from the National Oceanic and Atmospheric Administration is limited to only a few points along this coastal region and thus provides insufficient spatial coverage for robust predictions. Therefore, Zhao relied on simulated data from the ADvanced CIRCulation (ADCIRC) model, as this data covers a larger spatial domain and effectively captures the full complexity of storm surge events. Using ADCIRC, he and his collaborators generated a global dataset with over 48,000 synthetic hurricanes—including more than 13,000 in the North Atlantic basin—that offers broad spatial coverage around the world.
Next, Zhao introduced some of the key metrics of his model. “In real-world storm risk assessment, the quantity we care about is the peak water elevation at any location regardless of time,” he said. The corresponding equation measures storm surge for all time steps at location \(x\) according to meteorological forcing data like wind and pressure.
Although researchers typically model storm surge as a spatial temporal function over an entire domain, doing so for the entire Texas coastline is prohibitively costly; the mesh alone comprises millions of nodes. So, Zhao employed a point-based training approach to reduce the spatial and temporal dimensions. “Instead of predicting the full time series and interpolating, we learn the peak storm surge at each location directly,” he said. “And instead of time series data, we optimize the model for direct peak elevation prediction by using root mean square deviation.”
But by predicting each location independently, Zhao and his collaborators lose the spatial relationships between points because the loss function is no longer a sum over all points. “To address this, we incorporate spatial dependencies into our feature engineering pipeline,” Zhao said. In doing so, he turned to bathymetry: the study of the topography and depth of the ocean floor. Zhao focused on shallow water regions rather than open water, excluded locations with bathymetry values that were greater than 10 meters, and filtered the dataset to a region around the landfall position of the storm.
Zhao then spoke about the model training process. First, he tested the resulting model on a feedforward artificial neural network (ANN), which predicts peak storm surge by applying multiple nonlinear transformations to the input feature vector. He compared model performance with all 161 features versus a reduced set of 80 features that were selected by gradient boosting algorithms based on their importance. This technique captured overall trends fairly well.
However, the multilayer perceptron feedforward network learns feature correlations implicitly, while the self-attention mechanism explicitly models these dependencies. Given this distinction, Zhao further trained the model with a feature tokenization transformer (FTT) method and compared FTT models with 1, 16, and 32 embedding dimensions. The model with 32 dimensions achieved the lowest training loss.
Zhao concluded his presentation with a brief discussion about his efforts to fine tune the model for regional adaptation. “Storm surge dynamics vary globally, and different regions have distinct feature correlations,” he said. For both the ANN and FTT implementations, he first pretrained the model in high-correlation areas—such as the Gulf of Mexico—and then adapted region-specific models by refining the pretrained weights. In the future, Zhao and his colleagues hope to further optimize their model for specific storm-prone zones and validate it with historical hurricane events.
About the Author
Lina Sorg
Managing editor, SIAM News
Lina Sorg is the managing editor of SIAM News.

Related Reading

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
