
Deep Learning for Digital Pathology: Detecting Skin Diseases with Normalizing Flows
The skin is the largest organ of the human body. It serves as a barrier to a multitude of external influences, and thus plays an integral role in the body’s successful functioning. However, permanent exposure to certain substances and stimuli can cause skin damage and disease. These ailments range from minor irritations or sunburns to melanoma, an aggressive type of skin cancer. Here, we explore the ways in which mathematical concepts from deep learning can assist in the diagnosis of skin diseases by defining changes in the skin as out-of-distribution (OOD) samples from healthy tissue. Our model does not need to see examples of the diseases in training, which eliminates the need for time-consuming annotation processes.
Digital Pathology
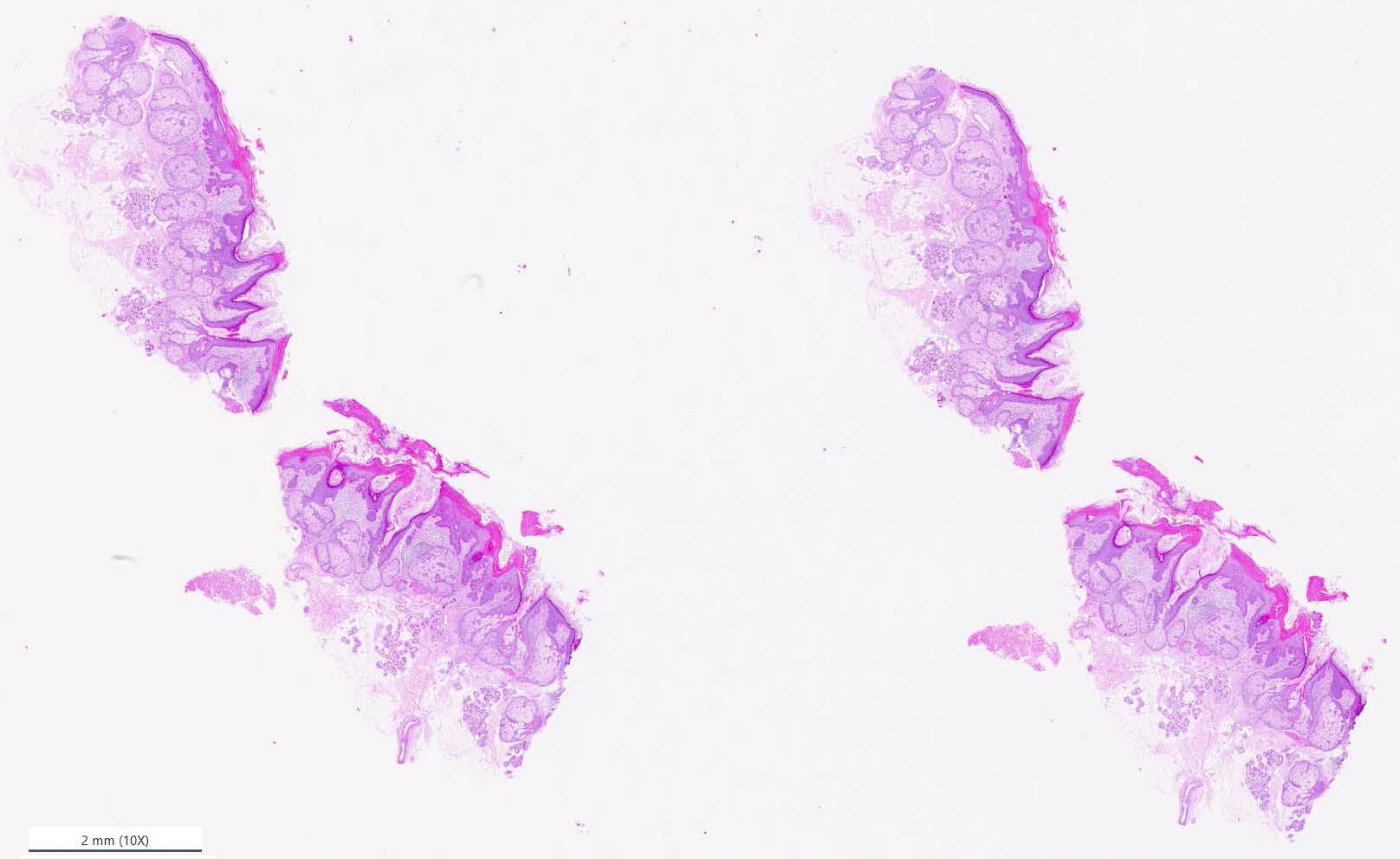
Pathology laboratories often use tissue samples from an affected area of the skin to diagnose disease. Pathologists cast the tissue in paraffin, cut it into fine slices, apply the slices to glass slides, and use a staining solution to highlight specific structures. Classically, the pathologists would then examine the sample under a microscope. In recent years, however, digital pathology—wherein pathologists generate high-resolution optical images of the slides and investigate them on a computer screen—has become increasingly commonplace. Figure 1 provides an image of tissue slices with a hematoxylin and eosin stain that produces the typical purple and pink color scheme.
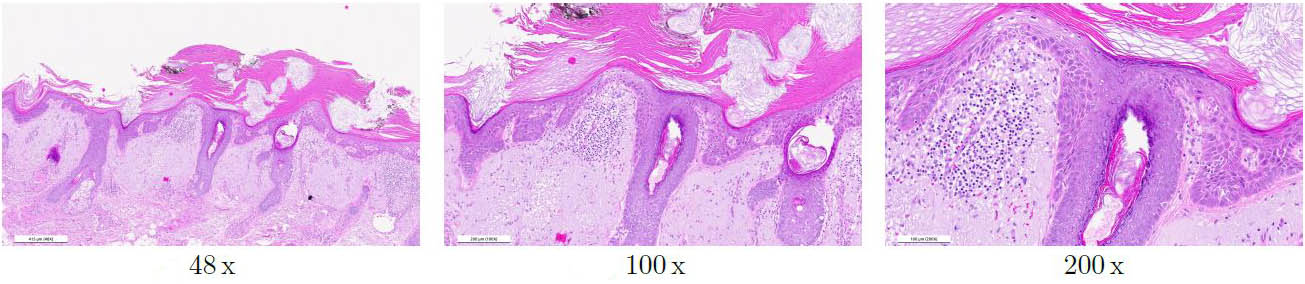
Digital pathology invites the possibility of image evaluation via mathematical methods. Several published papers in this field have addressed the detection of various disease patterns in skin [5, 8], breast [10], and prostate samples [1]. Nevertheless, the application of deep learning methods to digital pathology images is complex for several reasons. The first challenge is the large size of the scans, which necessitates their subdivision into smaller image patches. Secondly, users can examine the images at different magnification levels (just like under a microscope), where different image features are visible depending on the level (see Figure 2). Finally, hundreds of distinct diseases affect the skin. The annotation process for supervised deep learning models is tedious, and many diseases are so rare that it is impossible to collect extensive amounts of training data. In order to assist pathologists with diagnoses for all possible cases, we therefore assume that diseases are OOD data points from the distribution of healthy tissue. In this scenario, the model only needs to learn to identify healthy tissue.
Out-of-Distribution Detection with Normalizing Flows
We use normalizing flows (NFs) [12] to perform the OOD detection task by calculating the likelihood that a given input patch will fall within the target distribution of patches with healthy tissue. An easy-to-evaluate base distribution \(p_\mathbf{z}\) and an invertible, differentiable transformation \(T\) help with construction of the NFs. For the transformation, we use an invertible neural network \(T_\theta\) that is parameterized by \(\theta\). Our base distribution \(p_\mathbf{z}\) induces a distribution on the image space \(\mathbf{x} = T_\theta(\mathbf{z})\). Though the target distribution of patches with healthy tissue is generally unknown, we can calculate the likelihood via the change of variable theorem
\[p_\theta(x) = p_\mathbf{z}(T_\theta^{-1}(x)) |\det J_{T_\theta^{-1}}(x)|,\tag1\]
where \(J_{T_\theta^{-1}}(x)\) is the Jacobian of \(T_\theta^{-1}\).
Equation \((1)\) allows us to use maximum likelihood estimation to fit the parameters \(\theta\) [3]. In the training phase, we utilize images \(\{x^{(i)}\}_{i=1}^N\) from the unknown target distribution—i.e., the distribution of healthy tissue—to maximize the likelihood
\[\begin{eqnarray} \max L(\theta) &=& \sum_{i=1}^N \log(p_\theta(x^{(i)})) \\ &=& \sum_{i=1}^N \left( \log p(T_\theta^{-1}(x^{(i)})) + \log |\det J_{T_\theta}(T_\theta^{-1}(x^{(i)}))|\right). \end{eqnarray}\]
Doing so is equivalent to minimizing the Kullback-Leibler divergence between the unknown target distribution and the distribution that is induced by the NF [9].
The application of NFs to images faces a distinct challenge due to the high dimensionality of the data, and we must be prepared for corresponding phenomena in our base distributions. One such effect is the difference between the high-density region and the typical set, i.e., the set with a high volume of samples [7]. The distance between the two regions scales with \(\sqrt{d}\) for a standard Gaussian, where \(d\) is the dimensionality of the data. As a result, samples with a high likelihood might not represent the appearance of most samples in the distribution. In addition, OOD samples are assigned a higher likelihood for high-dimensional data than the in-distribution samples that are used for training. This observation goes against our intent to employ NFs as OOD detectives. One possible way out of this setback involves the use of a base distribution wherein the high-density region and typical set coincide [2]. As an alternative, researchers have proposed a typicality test with the help of the training and validation data [7]. This test considers new samples to be OOD if they are too far from the typical set. We follow this approach in our experiments.
Experiments with Actinic Keratosis
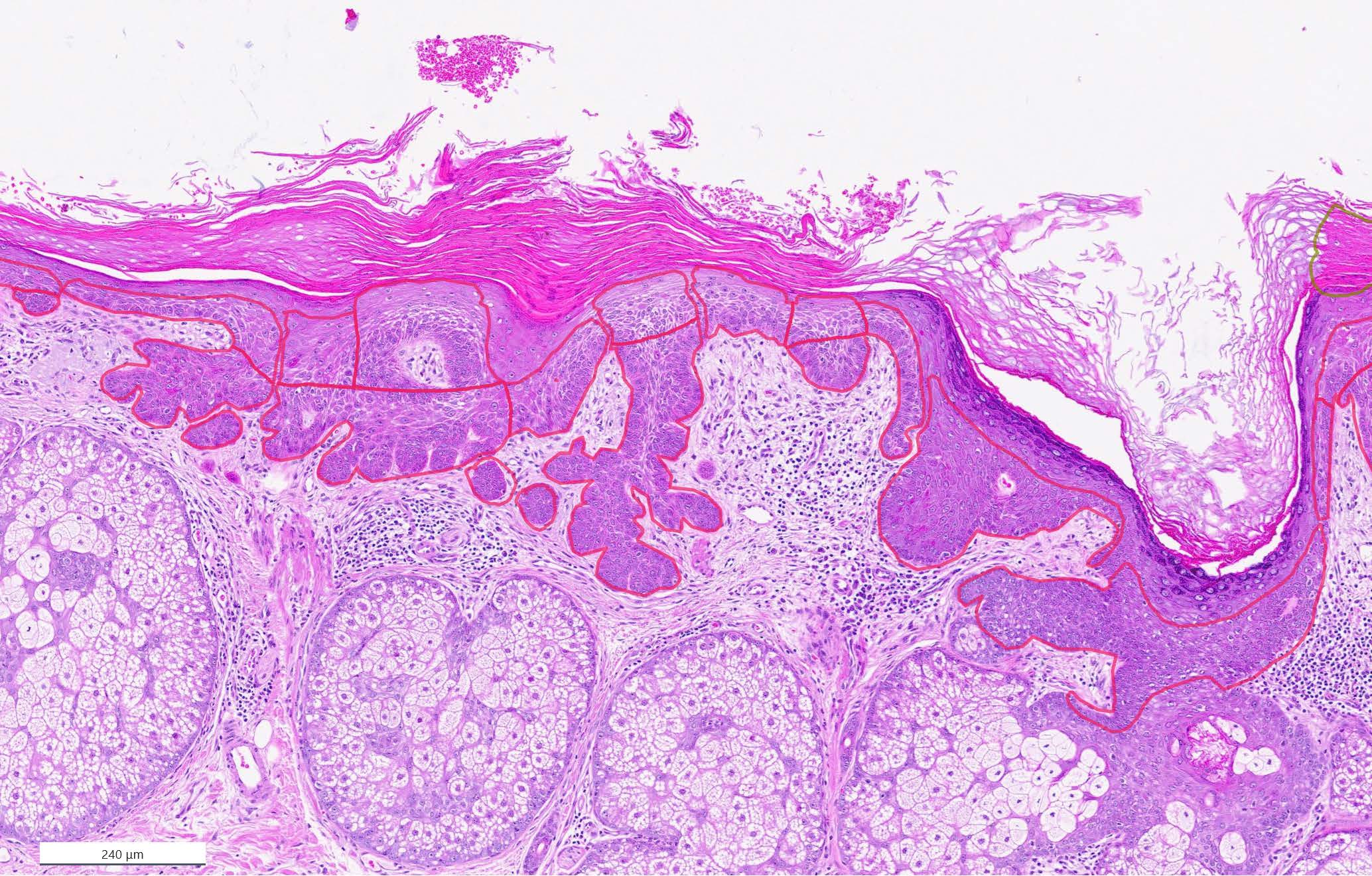
We extract RGB image patches of size 1,000 pixels by 1,000 pixels at magnifications of 50x, 100x, and 200x. We then train a separate NF on each level and choose a standard Gaussian as the base distribution and an invertible U-Net architecture [4] for the transformation \(T_\theta\). The patches for training and validation come from scans of healthy tissue regions; for the test set, we use patches with healthy tissue and patches with actinic keratosis (AK). AK is a precancerous skin lesion that can progress into cutaneous squamous cell carcinoma and represents one of the most common skin lesions in dermatology [6, 11]. Disease spread begins in the epidermis, the outermost layer of the skin (see Figure 3).

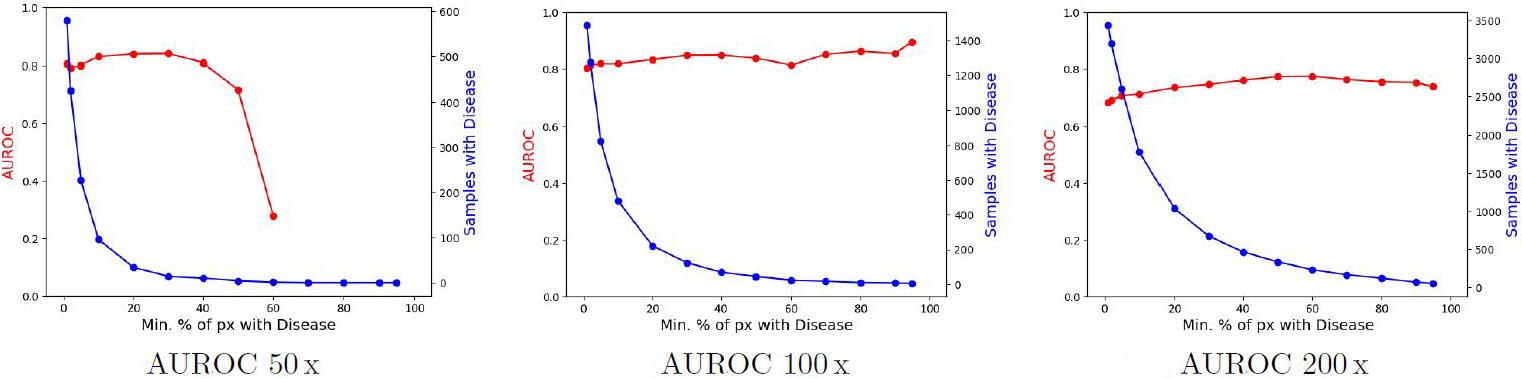
Figure 4 lists the number of patches in each set. Pixel-precise annotations by three medical experts are available as references for the areas with AK. To turn these segmentation masks into a single label for an image patch, we set a threshold for the relative area of AK above which a patch is considered diseased. We then vary this area threshold from one to 95 percent in all experiments to determine whether OOD detection depends on the affected area’s size. At each setting, we calculate the area under the receiver operating characteristic curve (AUROC) with \(\in [0,1]\) and use it as our performance measure to distinguish between healthy and diseased tissue.
Figure 5 illustrates the development of the AUROC scores at the three different magnification levels. The AUROC values remain relatively stable as the area threshold for AK assignment increases. These values almost always sit between 0.7 and 0.9, which is an excellent range for a model that has not seen any examples of AK in its training. The only exception is the model at 50x magnification, as performance drops significantly in AK areas that account for at least 40 percent of the entire patch. However, the data size is minimal — for example, no patches at this magnification level have AK that covers more than 60 percent of the patch area. In contrast, the models at 100x and 200x magnification can sufficiently detect both small and large AK areas in the tissue as OOD.
We have presented an OOD detection model based on NFs that can detect skin diseases in histological tissue sections. We tested the model on samples with AK and demonstrated a solid detection rate of the affected areas. In this context, the model had not seen any examples of the disease during training. The excellent performance with AK motivates the investigation of other disease patterns. Looking ahead, the application of saliency techniques could reveal more about the model’s performance and ultimately lead to its incorporation within the pathological routine.
Maximilian Schmidt delivered a minisymposium presentation on this research at the 2022 SIAM Conference on Mathematics of Data Science, which took place in San Diego, Ca., last year.
Ethics Vote and Acknowledgments: This study was performed in accordance with the approval of the ethics committee of Witten/Herdecke University (Proposal-No. 105/2022). It retrospectively analyzes patient samples from the clinical routine that have been processed in an anonymized way.
The author thanks Julius Balkenhol, Lutz Schmitz, and Thomas Dirschka for providing data and annotations of AK areas. This research was made possible by support for project “aisencia” from the EXIST Transfer of Research, the Federal Ministry for Economic Affairs and Climate Action of Germany, and the European Social Fund.
References
[1] Da Silva, L.M., Pereira, E.M., Salles, P.G., Godrich, R., Ceballos, R., Kunz, J.D., … Reis-Filho, J.S. (2021). Independent real-world application of a clinical-grade automated prostate cancer detection system. J. Pathol., 254(2), 147-158.
[2] Denker, A., Schmidt, M., Leuschner, J., & Maass, P. (2021). Conditional invertible neural networks for medical imaging. J. Imaging, 7(11), 243.
[3] Dinh, L., Krueger, D., & Bengio, Y. (2015). NICE: Non-linear independent components estimation. In Y. Bengio & Y. LeCun (Eds.), 3rd international conference on learning representations (ICLR 2015): Conference track proceedings.
[4] Etmann, C., Ke, R., & Schönlieb, C.-B. (2020). iUNets: Learnable invertible up- and downsampling for large-scale inverse problems. In 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP) (pp. 1-6). Institute of Electrical and Electronics Engineers.
[5] Jansen, P., Baguer, D.O., Duschner, N., Arrastia, J.L.C., Schmidt, M., Wiepjes, B., ... Griewank, K.G. (2022). Evaluation of a deep learning approach to differentiate Bowen’s disease and seborrheic keratosis. Cancers, 14(14), 3518.
[6] Landis, E.T., Davis, S.A., Taheri, A., & Feldman, S.R. (2014). Top dermatologic diagnoses by age. Dermatol. Online J., 20(4), 22368.
[7] Nalisnick, E., Matsukawa, A., Teh, Y.W., & Lakshminarayanan, B. (2019). Detecting out-of-distribution inputs to deep generative models using a test for typicality. Preprint, arXiv:1906.02994.
[8] Olsen, T.G., Jackson, B.H., Feeser, T.A., Kent, M.N., Moad, J.C., Krishnamurthy, S., … Soans, R.E. (2018). Diagnostic performance of deep learning algorithms applied to three common diagnoses in dermatopathology. J. Pathol. Inform., 9, 32.
[9] Papamakarios, G., Nalisnick, E., Rezende, D.J., Mohamed, S., & Lakshminarayanan, B. (2021). Normalizing flows for probabilistic modeling and inference. J. Mach. Learn. Res., 22, 1-64.
[10] Sandbank, J., Bataillon, G., Nudelman, A., Krasnitsky, I., Mikulinsky, R., Bien, L., … Vincent-Salomon, A. (2022). Validation and real-world clinical application of an artificial intelligence algorithm for breast cancer detection in biopsies. NPJ Breast Cancer, 8, 129.
[11] Schmitz, L., Oster-Schmidt, C., & Stockfleth, E. (2018). Nonmelanoma skin cancer – from actinic keratosis to cutaneous squamous cell carcinoma. J. Dtsch. Dermatol. Ges., 16(8), 1002-1013.
[12] Tabak, E.G., & Turner, C.V. (2013). A family of nonparametric density estimation algorithms. Commun. Pure Appl. Math., 66(2), 145-164.
About the Author
Maximilian Schmidt
Co-founder, aisencia
Maximilian Schmidt completed his Ph.D. on deep learning methods in inverse problems at the University of Bremen’s Center for Industrial Mathematics under the direction of Peter Maass. He is one of the co-founders of “aisencia,” a research project that investigates the transfer of deep learning methods for disease detection in tissue samples. His main area of interest involves linking mathematical models with data-driven approaches.

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
