
Don’t Matricize, Tensorize!
Tensor-tensor Algebras for Optimal Representations of Multiway Data
From medical imaging and scientific simulations to neural dynamics and more, multiway data is having its moment. This multiway moment is met with exciting questions about how to manipulate, analyze, and learn from data that are intrinsically multidimensional. This is where data analysis, the singular value decomposition (SVD), and tensors come into play.
The Holy Grail of Classical Data Analysis
Data analysis encapsulates methods to understand and utilize data effectively, often by extracting interpretable features and building compressed representations. The SVD is a powerful tool that tackles these common data analysis imperatives, including principal component analysis, linear inverse problems, and dimensionality reduction. Mathematically, the (economic) SVD decomposes any matrix \(\mathbf{A}\in \mathbb{C}^{n_1\times n_2}\) into
\[\mathbf{A}=\mathbf{U}\mathbf{\Sigma}\mathbf{V}^H=\sum^r_{i=1}\sigma_i\mathbf{U}(:,i)\mathbf{V}(:,i)^H, \tag1\]
where \(r=\textrm{rank}(\mathbf{A}).\) Here, \(\mathbf{U}\in\mathbb{C}^{n_1 \times r}\) and \(\mathbf{V}\in\mathbb{C}^{n_2 \times r}\) have unitary columns (e.g., \(\mathbf{U}^H\mathbf{U}=\mathbf{V}^H\mathbf{V}=\mathbf{I}_r,\) the \(r \times r\) identity matrix) and \(\mathbf{\Sigma} \in \mathbb{R}^{r\times r}\) is a diagonal matrix with real, non-negative diagonal entries (singular values) ordered from largest to smallest; i.e., \(\sigma_1 \geqslant \sigma_2 \geqslant \dotsb \geqslant \sigma_r >0,\) where \(\sigma_i :=\mathbf{\Sigma}(i,i).\)
We can readily understand the SVD from geometric, statistical, and algebraic perspectives. Geometrically, it diagonalizes \(\mathbf{A}\) through two unitary coordinate transformations. Statistically, the singular vectors (columns of \(\mathbf{U}\) and \(\mathbf{V}\)) align in unitary directions of maximal variance of the data stored in \(\mathbf{A};\) the singular values quantify the standard deviation per direction. Algebraically, the SVD is a rank-revealing decomposition where the rank is determined by the number of nonzero singular values. The ordering of the singular values gives rise to a natural truncation strategy to produce a low-rank (i.e., compressed) approximation of \(\mathbf{A};\) namely, the truncated SVD retains terms that correspond to the largest singular values. This strategy leads to the beautiful Eckart-Young theorem [2], which states that for \(k \leqslant r,\) the truncated SVD \(\mathbf{A}_k\) is the optimal rank-\(k\) (or less) approximation to the rank-\(r\) matrix \(\mathbf{A}\) in the Frobenius norm, i.e.,
\[\mathbf{A}_k=\sum^k_{i=1}\sigma_i\mathbf{U}(:,i)\mathbf{V}(:,i)^H=\underset{\textrm{rank}(\mathbf{B})\leqslant k}{\textrm{argmin}} ||\mathbf{A}-\mathbf{B}||_F.\]
Because of its combination of explicability, compressibility, and optimality properties, we playfully call the SVD the “holy grail” of data analysis.
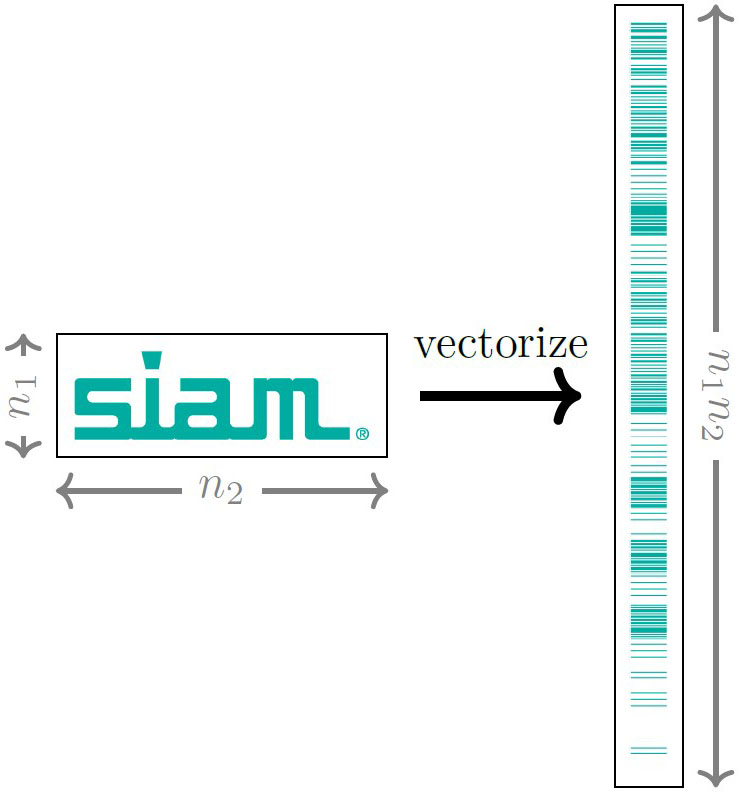
The SVD’s “divine” properties come with one major assumption: that the underlying data are represented by a matrix. As a result, many data analysis pipelines begin with a preprocessing step that reshapes the data into a matrix form before applying SVD-based methods. Such matricization can hide valuable high-dimensional correlations (see Figure 1). This realization has propelled the modern search for a multiway analog of the SVD — a decomposition that gives rise to interpretable features, compressible representations, and optimality guarantees while simultaneously respecting native multilinear structure.
The Quest for the Tensor Holy Grail
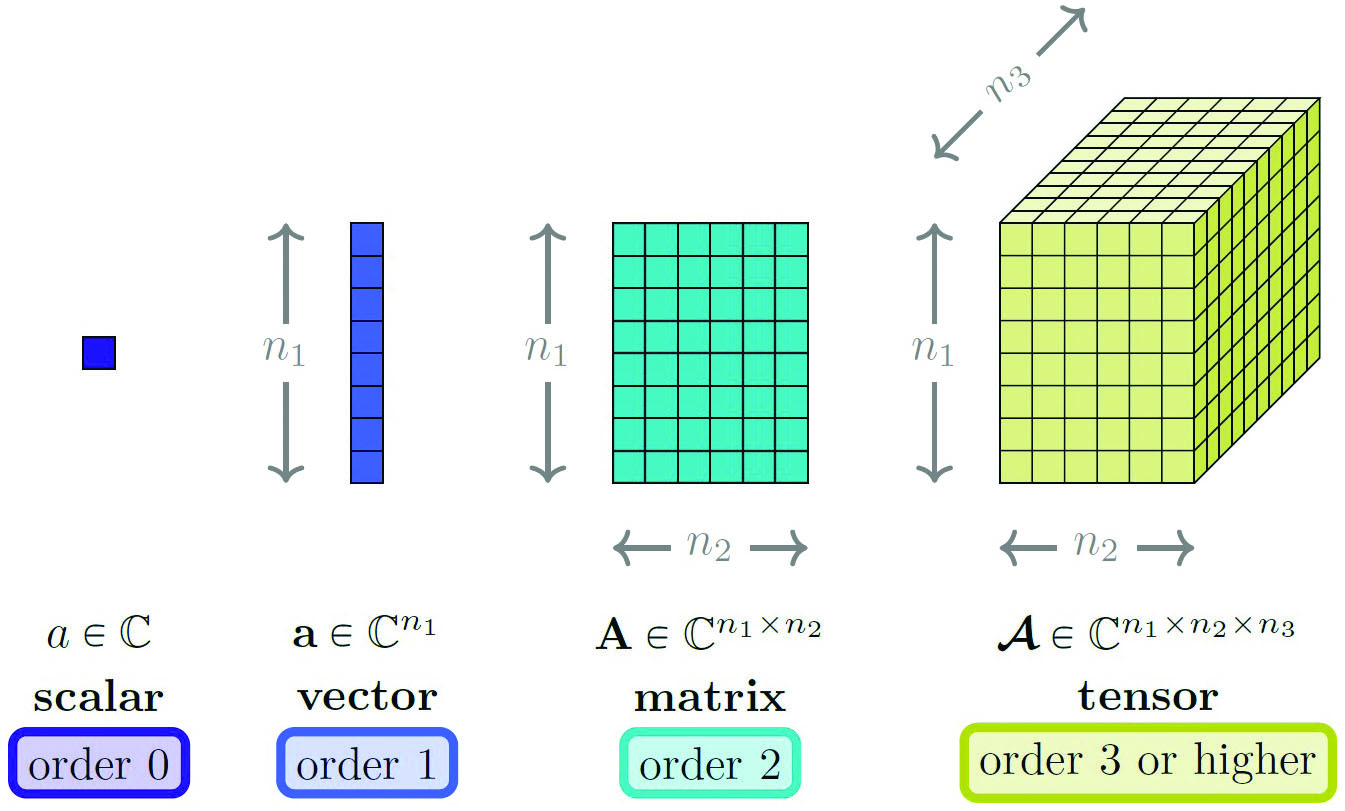
Before delving into multiway SVDs, let’s first introduce tensors to encode multidimensionality mathematically. Tensors serve as high-dimensional extensions of the building blocks of linear algebra: scalars (order-\(0\) tensors), vectors (order-\(1\) tensors), and matrices (order-\(2\) tensors). We use the term “tensor” to refer to any multiway array or multilinear operator of order-\(3\) or higher (see Figure 2).
The quest for the tensor holy grail—a multiway analog of the SVD and a multilinear Eckart-Young theorem—has inspired the development of a host of tensor decompositions [1]. Among the earliest strategies is the canonical polyadic or CANDECOMP/PARAFAC (CP) decomposition, which, in the spirit of the SVD summation formulation in \((1),\) expresses multiway arrays as a sum of rank-\(1\) tensors. This summation form yields interpretable CP factors that are fairly unique without additional constraints. Other classical tensor factorization strategies—namely the Tucker decomposition and its popular variant, the higher-order SVD (HOSVD)—generalize the coordinate transformation formulation of the SVD in \((1)\) to multiway arrays. As a result, the HOSVD serves as a high-dimensional form of principle component analysis and is well suited for multilinear dimensionality reduction and data compression. Beyond multiway data analysis, modern tensor network representations like tensor train (TT) impose practical tensorial structure in order to solve extremely high-dimensional problems (e.g., order-\(d\) for large \(d\)) and break the infamous curse of dimensionality. The wide range of tensor decompositions have impacted multiple scientific disciplines, including psychometrics, chemometrics, computer vision, and quantum chemistry.
While these tensor factorizations inherit characteristics of the matrix SVD, all lack one crucial algebraic property: provable optimality (i.e., the Eckart-Young theorem does not hold). In fact, many cornerstones of linear algebra fail when multilinearity is introduced (e.g., determining the CP rank is NP-hard). Borrowing from a familiar catchphrase, we call this phenomenon the curse of multidimensionality.
Tensor-tensor Algebras: Breaking the Curse of Multidimensionality
The story of tensor-tensor algebras begins with a decades-long open question: Can tensor-based approaches mirror their matrix-based counterparts? In other words, can a tensor framework break the curse of multidimensionality? The seminal work of Misha Kilmer and Carla Martin [5] offered a key breakthrough called the \(t\)-product, a tensor-tensor product that mimicked matrix multiplication. Subsequent research extended to a family of matrix-mimetic tensor operators that preserved familiar linear algebraic properties [3]. Our work leverages these matrix-mimetic operators to achieve our ultimate goal: an Eckart-Young-like theorem for tensors [4].
Matrix-mimetic Tensor Operations
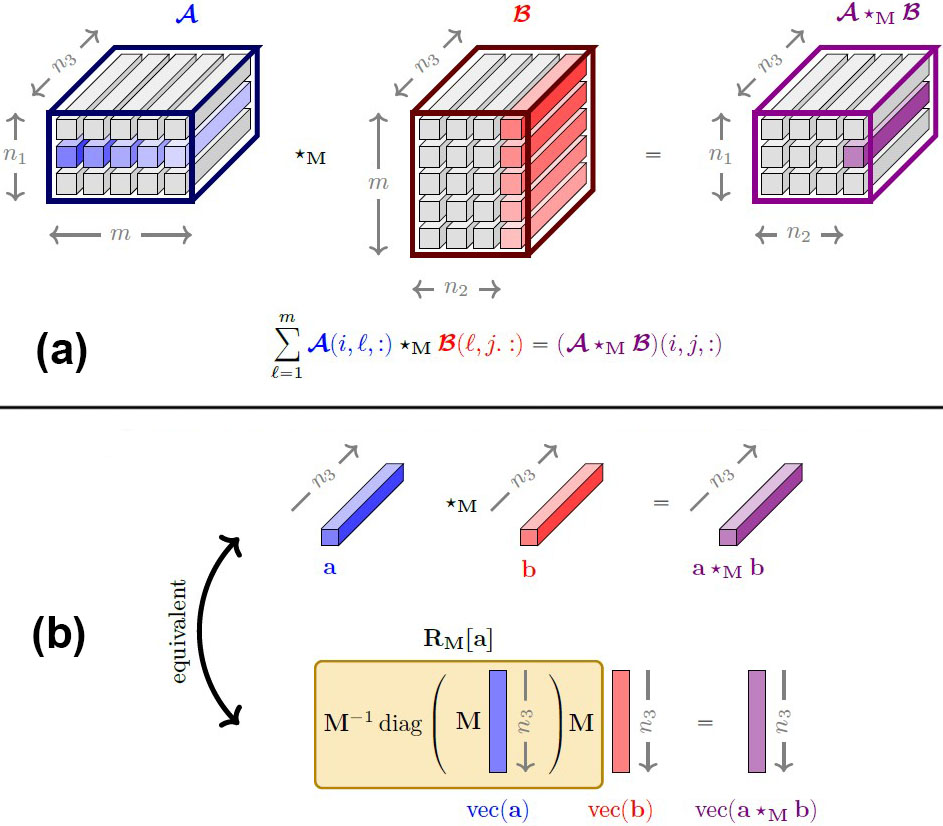
To construct a tensor operation that “looks and feels” like matrix multiplication, we view an order-\(3\) tensor \(\pmb{\mathcal{X}} \in \mathbb{C}^{n_1\times n_2 \times n_3}\) as an \(n_1 \times n_2\) matrix where each entry is a \(1 \times 1 \times n_3\) array or tube (see Figure 3a). From this perspective, scalars are to matrices what tubes are to tensors. In the same way that matrix-vector products stem from scalar multiplication, tensor-tensor products are built on tubal operations. These principles extend to tensors of arbitrary order, beyond order-\(3\) [6].
Let us denote the tubal product as \(\star_{\mathbf{M}},\) pronounced “star-M,” where \(\mathbf{M}\in \mathbb{C}^{n_3\times n_3}\) is a user-defined invertible matrix. Given tubes \(\mathbf{a}, \mathbf{b} \in \mathbb{C}^{1 \times 1 \times n_3},\) we define tubal multiplication \(\mathbf{a}\star_{\mathbf{M}} \mathbf{b} \in \mathbb{C}^{1 \times 1 \times n_3}\) (see Figure 3b) by
\[\mathbf{a}\star_{\mathbf{M}} \mathbf{b}=\textrm{tube}(\mathbf{R_M}[\mathbf{a}]\textrm{vec}(\mathbf{b})), \qquad \textrm{where} \qquad \mathbf{R_M}[\mathbf{a}]=\mathbf{M}^{-1}\textrm{diag}(\mathbf{M}\textrm{vec}(\mathbf{a}))\mathbf{M} \tag2\]
We say that the action of \(\mathbf{a}\) on \(\mathbf{b}\) is equivalent to the multiplication by a structured matrix \(\mathbf{R_M}[\mathbf{a}]\) parameterized by \(\mathbf{a}.\) Consequently, tubal multiplication operates under an algebraic ring operation. The set of all structured matrices \(\mathbf{R_M}[\cdot]\) forms a matrix subalgebra; this is to what we refer when we say “tensor-tensor algebra.”
The underlying structure of \(\mathbf{R_M}[\cdot]\) and the resulting algebra depends on the choice of invertible matrix \(\mathbf{M}.\) For example, the matrices \(\mathbf{M}=\mathbf{I}\) (the identity matrix) and \(\mathbf{M}=\mathbf{F}\) (the discrete Fourier transform matrix) respectively lead to the structured operators
\[\mathbf{R_I}[\mathbf{a}]=\textrm{diag}(\mathbf{a})= \begin{pmatrix} a_1 & & & \\ & a_2 & & \\ & & \ddots & \\ & & & a_{n_3} \end{pmatrix} \qquad \textrm{and} \qquad \mathbf{R_F}[\mathbf{a}]=\textrm{circ}(\mathbf{a})= \begin{pmatrix} a_1 & a_{n_3} & \dotsc & a_2 \\ a_2 & a_1 & \dotsc & a_3 \\ \vdots & \vdots & \ddots & \vdots \\ a_{n_3} & a_{{n_3}-1} & \cdots & a_1 \end{pmatrix}. \tag3\]
The former gives rise to the algebra defined by the Hadamard pointwise product, and the latter induces the algebra of circulants, which is the foundation of the original \(t\)-product.
With tubal multiplication in place, we extend the \(\star_{\mathbf{M}}\)-product through a tubal entry-wise definition (see Figure 3a). Given tensors \(\pmb{\mathcal{A}}\in\mathbb{C}^{n_1\times m \times n_3}\) and \(\pmb{\mathcal{B}}\in\mathbb{C}^{m\times n_2 \times n_3},\) the \(\star_{\mathbf{M}}\)-product \(\pmb{\mathcal{A}}\star_{\mathbf{M}}\pmb{\mathcal{B}}\in\mathbb{C}^{n_1\times n_2 \times n_3}\) is
\[(\pmb{\mathcal{A}}\star_{\mathbf{M}}\pmb{\mathcal{B}})(i,j,:)=\sum^m_{\ell=1}\pmb{\mathcal{A}}(i,\ell,:)\star_{\mathbf{M}}\pmb{\mathcal{B}}(\ell,j,:) \quad \textrm{for} \quad i=1,...,n_1 \enspace \textrm{and} \enspace j=1,...,n_2. \tag4\]
A matrix-mimetic, mathematical framework for tensor operators enables natural generalizations of properties such as a \(\star_{\mathbf{M}}\)-identity (e.g., \(\pmb{\mathcal{I}}\star_{\mathbf{M}}\pmb{\mathcal{A}}=\pmb{\mathcal{A}}\star_{\mathbf{M}}\pmb{\mathcal{I}}=\pmb{\mathcal{A}}\)), \(\star_{\mathbf{M}}\)-transposition (e.g., \((\pmb{\mathcal{A}}\star_{\mathbf{M}}\pmb{\mathcal{B}})^H=\pmb{\mathcal{B}}^H\star_{\mathbf{M}}\pmb{\mathcal{A}}^H\)), and \(\star_{\mathbf{M}}\)-unitary (e.g., \(\pmb{\mathcal{Q}}^H\star_{\mathbf{M}}\pmb{\mathcal{Q}}=\pmb{\mathcal{I}}\)). Notably, we obtain a \(\star_{\mathbf{M}}\)-analog of the SVD.
Provable Optimality
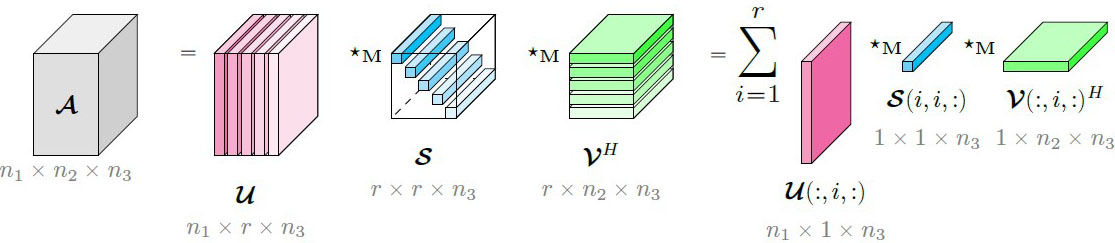
Like its matrix counterpart in \((1)\), the (economic) \(\star_{\mathbf{M}}\)-SVD in Figure 4 factorizes any tensor \(\pmb{\mathcal{A}}\in\mathbb{C}^{n_1\times n_2\times n_3}\) as
\[\pmb{\mathcal{A}}=\pmb{\mathcal{U}}\star_{\mathbf{M}}\pmb{\mathcal{S}}\star_{\mathbf{M}}\pmb{\mathcal{V}}^H=\sum^r_{i=1}\pmb{\mathcal{U}}(:,i,:)\star_{\mathbf{M}}\pmb{\mathcal{S}}(i,i,:)\star_{\mathbf{M}}\pmb{\mathcal{V}}(:,i,:)^H. \tag5\]
Matrix mimeticity guarantees that the factors of \(\star_{\mathbf{M}}\)-SVD retain familiar properties: (i) \(\star_{\mathbf{M}}\)-unitary of the left and right singular tensors, \(\pmb{\mathcal{U}}\) and \(\pmb{\mathcal{V}};\) (ii) tubal-diagonal structure of \(\pmb{\mathcal{S}}\) with ordered singular tubes \(|| \pmb{\mathcal{S}}(1,1,:)||_F \geqslant||\pmb{\mathcal{S}}(2,2,:)||_F\geqslant \cdots \geqslant || \pmb{\mathcal{S}}(r,r,:)||_F \geqslant 0; \) and (iii) \(\star_{\mathbf{M}}\)-rank of \(\pmb{\mathcal{A}}\) given by the number of nonzero singular tubes.
The piéce de résistance is that the \(\star_{\mathbf{M}}\)-SVD satisfies an Eckart-Young-like theorem for tensors, a unique advantage of the \(\star_{\mathbf{M}}\)-framework. In short, we have found the tensor holy grail! Formally, under appropriate assumptions—namely, that \(\mathbf{M}\) is a nonzero multiple of a unitary matrix—the truncated \(\star_{\mathbf{M}}\)-SVD produces the best low-\(\star_{\mathbf{M}}\)-rank approximation of a \(\star_{\mathbf{M}}\)-rank-\(r\) tensor \(\pmb{\mathcal{A}};\) i.e., for \(k \leqslant r,\)
\[\pmb{\mathcal{A}}_k=\sum^k_{i=1}\pmb{\mathcal{U}}(:,i,:)\star_{\mathbf{M}}\pmb{\mathcal{S}}(i,i,:)\star_{\mathbf{M}}\pmb{\mathcal{V}}(:,i,:)^H= \underset{\star_{\mathbf{M}}\textrm{-rank}(\pmb{\mathcal{B}})\leqslant k}{\textrm{argmin}} ||\pmb{\mathcal{A}}-\pmb{\mathcal{B}}||_F. \tag6\]
The implications of \((6)\) go beyond the optimality of low-\(\star_{\mathbf{M}}\)-rank representations. Notably, for any \(\mathbf{M}\) that satisfies the same assumptions as \((6)\) and a shared truncation parameter \(k,\) the truncated \(\star_{\mathbf{M}}\)-SVD of tensor data \(\pmb{\mathcal{A}} \in \mathbb{C}^{n_1 \times n_2 \times n_3}\) is guaranteed to be more accurate than the truncated matrix SVD of a matricized version of the data \(\mathbf{A} \in \mathbb{C}^{n_1 \times n_3 \times n_2};\) i.e.,
\[{\color{gray}{(\star_{\mathbf{M}}\textrm{-Eckhart-Young error})}} \quad ||\pmb{\mathcal{A}}-\pmb{\mathcal{A}}_k||_F \leqslant ||\mathbf{A}-\mathbf{A}_k ||_F \quad {\color{gray}{(\textrm{matrix Eckhart-Young error)}}}, \tag7\]
where \(\mathbf{A}(:,j)=\textrm{vec}(\pmb{\mathcal{A}}(:,j,:))\) for \(j=1,...,n_2.\) Similar statements can be proven when comparing the \(\star_{\mathbf{M}}\)-SVD to other tensor decompositions that rely on intermediate matricization, such as the HOSVD and TT factorization (see Animation 1).
Unifying Algebraic Framework
Beyond performance comparisons, many points of connection exist between the \(\star_{\mathbf{M}}\)-framework and other factorization strategies. As indicated in \((7),\) we can relate the \(\star_{\mathbf{M}}\)-SVD and the matrix SVD through a specific matricization of the data. Moreover, we can employ a clever choice of tensor-tensor algebra to express the HOSVD as the \(\star_{\mathbf{M}}\)-product of special factor tensors. We can even use other multiway frameworks to improve \(\star_{\mathbf{M}}\)-representations, such as storing the \(\star_{\mathbf{M}}\)-SVD in CP format to further reduce computational overhead. The rigorous algebraic foundations of the \(\star_{\mathbf{M}}\)-framework reveal these surprising and useful links between multiway methods.
Animation 1. Compression of MATLAB’s traffic video stored as a width\(\times\)time\(\times\)height tensor \(\pmb{\mathcal{A}}\in\mathbb{R}^{120 \times 120 \times 160}.\) For comparable storage costs (higher compression ratios are better), the \(\star_{\mathbf{M}}\)-SVD with \(\mathbf{M}=\mathbf{F}\)—the discrete Fourier transform matrix—produces a more accurate approximation (lower relative error) than the higher-order singular value decomposition (HOSVD). Both tensor-based approaches outperform the matrix SVD, which loses spatial correlations from vectorizing the video frames. By using inherently multilinear operations and avoiding intermediate matricization, the \(\star_{\mathbf{M}}\)-SVD produces the sharpest approximation overall. See the online version of this article for a corresponding animation. Figure courtesy of the author.
A Call to Multidimensional Action
We end this overview of matrix-mimetic tensor-tensor algebras with a call to action. Join us in pursuing novel applications like precision medicine [8]; developing new computational tools, such as optimal tensor-tensor-tensor products [9]; and pushing the algebraic framework to infinity and beyond [7]. Most importantly, we encourage readers to think multidimensionally; many data and operators are inherently high-dimensional, and modern tensor tools can help get the most out of this rich multiway information.
In short, don’t matricize, tensorize!
References
[1] Ballard, G., & Kolda, T.G. (2025). Tensor decompositions for data science. Cambridge, UK: Cambridge University Press.
[2] Eckart, C., & Young, G. (1936). The approximation of one matrix by another of lower rank. Psychometrika, 1(3), 211-218.
[3] Kernfeld, E., Kilmer, M., & Aeron, S. (2015). Tensor-tensor products with invertible linear transforms. Linear Algebra Appl., 485, 545-570.
[4] Kilmer, M.E., Horesh, L., Avron, H., & Newman, E. (2021). Tensor-tensor algebra for optimal representation and compression of multiway data. Proc. Natl. Acad. Sci., 118(28), e2015851118.
[5] Kilmer, M.E., & Martin, C.D. (2011). Factorization strategies for third-order tensors. Linear Algebra Appl., 435(3), 641-658.
[6] Martin, C.D., Shafer, R., & LaRue, B. (2013). An order-\(p\) tensor factorization with applications in imaging. SIAM J. Sci. Comput., 35(1), A474-A490.
[7] Mor, U., & Avron, H. (2025). Quasitubal tensor algebra over separable Hilbert spaces. Preprint, arXiv:2504.16231.
[8] Mor, U., Cohen, Y., Valdés-Mas, R., Kviatcovsky, D., Elinav, E., & Avron, H. (2022). Dimensionality reduction of longitudinal ’omics data using modern tensor factorizations. PLOS Comput. Biol., 18(7), e1010212.
[9] Newman, E., & Keegan, K. (2025). Optimal matrix-mimetic tensor algebras via variable projection. SIAM J. Matrix Anal. Appl., 46(3), 1764-1790.
About the Author
Elizabeth Newman
Assistant professor, Tufts University
Elizabeth Newman is an assistant professor in the Department of Mathematics at Tufts University and a 2025-2026 Merrin Faculty Fellow. She earned her Ph.D. from Tufts in 2019. Newman received an Air Force Fiscal Year 2025 Young Investigator Program Award and is a joint recipient of the 2025 SIAM Activity Group on Computational Science and Engineering Best Paper Prize.


Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
