
Foundation Models for Physiological Data
Foundation models are large machine learning models that are trained on vast datasets with self-supervised learning algorithms. They exhibit remarkable generalization and robustness across tasks like natural language processing, audio segmentation, and computer vision; notable examples include BERT [3], GPT [1], and Llama [5]. Inspired by this success, researchers are working to develop foundation models for physiological data, such as photoplethysmography (PPG) and electrocardiogram (ECG) signals. The goal is to explore whether foundation models that are trained with physiological data can enable next-generation applications in health monitoring, diagnosis, and personalized medicine, thereby empowering advances in smart healthcare.
![<strong>Figure 1.</strong> Model architecture of GPT-PPG, a generative pretrained transformer model that measures photoplethysmography (PPG) signals. Figure courtesy of [2].](/media/mahd1dmn/figure1.jpg)
Foundation models are pretrained with large-scale datasets to learn generalized representations of data without the need for extensive labeled examples. Their architectures, often based on transformers, effectively capture long-term dependencies and patterns in time series data. Models like GPT and BERT use self-supervised learning techniques that include masked token prediction and next-token generation. In the context of healthcare, physiological signals—e.g., PPG, ECG, and electroencephalography—share structural similarities with sequential text data. These similarities pave the way for the adaptation of foundation models to clinical applications, such as detecting atrial fibrillation (AF) or monitoring blood pressure and heart rate.
GPT-PPG
At the forefront of this innovation is GPT-PPG: a generative pretrained transformer model that is specifically designed for PPG signals [2]. PPG is a noninvasive method that measures blood volume changes in the microvascular tissue bed and plays a critical role in clinical and consumer health monitoring. GPT-PPG adapts the standard GPT architecture to accommodate the continuous nature of PPG signals. This model—which is pretrained on a dataset of over 200 million 30-second PPG segments from more than 25,000 hospitalized adult patients—demonstrates exceptional performance across various scenarios, including heart rate estimation, signal denoising, and AF detection. GPT-PPG notably excels in regressive tasks, leveraging its inherent ability to reconstruct and predict signal sequences. Unlike traditional methods that require task-specific fine-tuning, this model can perform these tasks with minimal tuning in many cases.
Figure 1 outlines the model architecture of GPT-PPG, which builds upon the foundational principles of the GPT framework while introducing targeted modifications to enhance its ability to process continuous physiological signals. It specifically employs patch tokenization, which segments normalized PPG signals into non-overlapping patches — each of which represents one second of data, roughly corresponding to one heartbeat. These patches serve as tokens to effectively reduce sequence length and improve computational efficiency. To capture temporal dependencies within sequential data, GPT-PPG incorporates rotary positional embeddings and efficient implementations of attention mechanisms. The model also replaces traditional layer normalization with root mean square normalization, which facilitates smoother training dynamics and enhances gradient stability. These architectural refinements collectively optimize GPT-PPG to handle physiological signals with greater precision and efficiency.
![<strong>Figure 2.</strong> Model architecture of MOMENT, a generalist model that is trained on diverse datasets that span multiple domains. Figure courtesy of [4].](/media/mxflzzwy/figure2.jpg)
GPT-PPG demonstrates exceptional performance across a wide range of downstream tasks. The model’s derivation of heart rate from raw PPG signals is state of the art, even in challenging conditions that involve noise or motion artifacts; it likewise excels in the estimation of blood pressure and detection of AF. As was aforementioned, one of the model’s standout features is its generative ability to reconstruct noisy PPG signals without the need for fine-tuning — a signal denoising capability that is particularly valuable in wearable device applications, where signal quality is frequently compromised.
Generalist Versus Specialist Foundation Models
While GPT-PPG is a specialist model that is trained exclusively on PPG signals, recent research in artificial intelligence (AI) has explored the development of generalist models like MOMENT [4] that are trained on diverse datasets of time series data from multiple domains (see Figure 2). MOMENT’s ability to integrate and process data from different sources—such as weather, traffic, and physiological signals—demonstrates the versatility of generalist models. Unlike GPT-PPG, MOMENT is pretrained with masked modeling, wherein parts of the input signal are masked during the training phase and a prediction head reconstructs the masked signal. After pretraining is complete, the prediction head is discarded but the encoder is preserved to extract fine-grained feature representations.
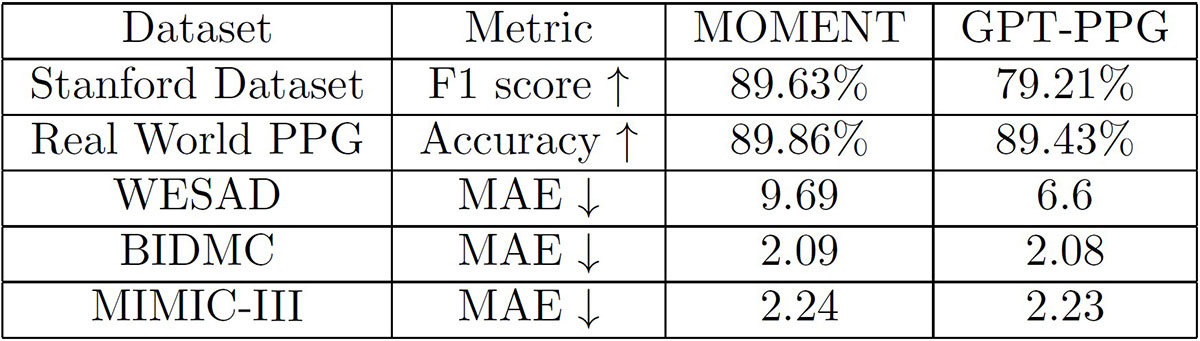
Given the two types of foundation models, we pose the following question: Can a generalist foundation model outperform a specialist model, even when the downstream tasks are specific to the specialist model’s domain? We use PPG signals to investigate this question and establish an organized PPG dataset repository for various types of downstream tasks to serve as a benchmark for the evaluation of foundation model performance, selecting a diverse set of downstream tasks that span five datasets (see Figure 3).

Using a 4:1:1 ratio, we randomly split the data into training, validation, and test sets based on participant identifiers. We select the model with the best performance on the validation set and assess its performance on the test set, utilizing both MOMENT-large (which has 385 million parameters) and GPT-PPG-large (which has 345 million parameters). Figure 4 lists the preliminary results. We see that the outcomes across the two models are very similar; MOMENT shows slightly better performance in classification tasks, while GPT-PPG performs better on regression tasks. Additional experiments are necessary to draw more definitive conclusions.
Challenges, Conclusions, and Future Directions
While the development of foundation models that can handle physiological data is undoubtedly an exciting frontier, several challenges remain. For example, we must collect a wide variety of training data with different devices, body parts, and sampling rates to account for the diversity of human physiology. Additionally, we need to prioritize ethical considerations—such as data privacy and equitable access to AI tools—to build trust and ensure fairness.
To further harness these models’ capabilities, we can work to extend them to multi-channel inputs and conditioning information, e.g., demographic data for personalization. Yet another direction for model analysis is interpretability, which can guide us in neuron probing and distillation for compression. Note that GPT-PPG and MOMENT are both attention-based models, which is convenient for interpretability studies.
Future research in this area should explore hybrid approaches that combine the strengths of specialist and generalist models. Techniques such as transfer learning and multimodal integration could enhance the adaptability and robustness of specialist models like GPT-PPG while retaining their understanding of general time series data.
The emergence of GPT-PPG and similar foundation models signals a new era in AI for healthcare, where advanced diagnostics and monitoring tools are well within reach. By harnessing AI’s power to analyze complex physiological data, these models offer a scalable, efficient, and robust solution to improve health outcomes. As ongoing research continues to push the limits, innovation and collaboration between clinicians and AI scientists will define the future of healthcare, unlocking AI’s full potential for patients worldwide.
Xiao Hu delivered a minisymposium presentation on this research at the 2024 SIAM Conference on Mathematics of Data Science, which took place in Atlanta, Ga., last October.
References
[1] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., … Zoph, B. (2023). GPT-4 technical report. Preprint, arXiv:2303.08774.
[2] Chen, Z., Ding, C., Modhe, N., Lu, J., Yang, C., & Hu, X. (2024). Adapting a generative pretrained transformer achieves SOTA performance in assessing diverse physiological functions using only photoplethysmography signals: A GPT-PPG approach. In AAAI 2024 spring symposium on clinical foundation models. Stanford, CA: Association for the Advancement of Artificial Intelligence.
[3] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the Association for Computational Linguistics: Human language technologies (pp. 4171-4186). Minneapolis, MN: Association for Computational Linguistics.
[4] Goswami, M., Szafer, M., Choudhry, A., Cai, Y., Li, S., & Dubrawski, A. (2024). MOMENT: A family of open time-series foundation models. In ICML'24: Proceedings of the 41st international conference on machine learning (pp. 16115-16152). Vienna, Austria: Association for Computing Machinery.
[5] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., … Lample, G. (2023). LLaMA: Open and efficient foundation language models. Preprint, arXiv:2302.13971.
About the Authors
Saurabh Kataria
Postdoctoral fellow, Emory University
Saurabh Kataria is a postdoctoral fellow in the Nell Hodgson Woodruff School of Nursing at Emory University, where he builds physiological foundation models for a variety of downstream applications. He completed his Ph.D. in audio processing and machine learning at Johns Hopkins University in 2023.

Yi Wu
Assistant professor, University of Oklahoma
Yi Wu is an assistant professor in the School of Computer Science at the University of Oklahoma. He completed his Ph.D. in electrical engineering and computer science at the University of Tennessee, Knoxville, under the supervision of Jian Liu, and then served as a postdoctoral researcher at the Center for Data Science at Emory University, where he worked with Xiao Hu. Wu’s research lies at the intersection of mobile sensing, human-computer interaction (HCI), and cybersecurity, with a focus on the application of machine learning and signal processing to enable intelligent, privacy-aware applications in health monitoring, HCI, and Internet of Things systems.

Xiao Hu
Professor, Emory University
Xiao Hu is a professor, Asa Griggs Candler Chair of Nursing Data Science, and associate director of the Center for Data Science within the Nell Hodgeson Woodruff School of Nursing at Emory University. He serves as the editor-in-chief of Physiological Measurement. Hu leads a research group of diverse expertise in computational and health sciences that pursues translational projects in a variety of medicine and nursing fields.

Related Reading
Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
