
Fusing Artificial Intelligence and Optimization with Trustworthy Optimization Proxies
Recent years have seen significant interest in the fusion of machine learning (ML) and optimization for a variety of engineering applications [2, 11]. Optimization technologies are widely successful in industry; they help to dispatch power grids, route transportation and logistics systems, plan and operate supply chains, and schedule manufacturing systems. However, these technologies still face computational challenges in certain applications. For instance, real-time constraints may prevent the production of solutions, or planners and operators in the loop might require fast interactions with the underlying decision support systems.
Fortunately, engineering applications typically operate on physical infrastructures that change relatively slowly. As a result, optimization technologies must repeatedly solve the same core optimization problem on instances that are somewhat similar. These considerations have inspired the idea that ML could learn such parametric optimization problems and replace optimization altogether. Consider the parametric optimization problem
\[\min\limits_{\mathbf{y}} f_\mathbf{x}(\mathbf{y}) \mbox{ subject to } \mathbf{h}_\mathbf{x}(\mathbf{y}) = 0 \ \; \textrm{and} \ \; \mathbf{g}_\mathbf{x}(\mathbf{y}) \geq 0, \tag1\]
where \(\mathbf{x}\) represents instance parameters that determine the objective function \(f_\mathbf{x}\) and the constraints \(\mathbf{h}_\mathbf{x}\) and \(\mathbf{g}_\mathbf{x}\). We may view this optimization as mapping from an input \(\mathbf{x}\) to an output \(\mathbf{y}\) that represents its optimal solution (or a selected optimal solution). In response, we can train a ML model—such as a deep neural network—to approximate this mapping via empirical risk minimization under constraints. Unfortunately, such an approximation is typically unsatisfactory for engineering tasks; because they are regressions, the ML predictions are unlikely to satisfy the problem constraints and may have significant consequences when optimization models assist with the operation of physical infrastructures.
Optimization Proxies
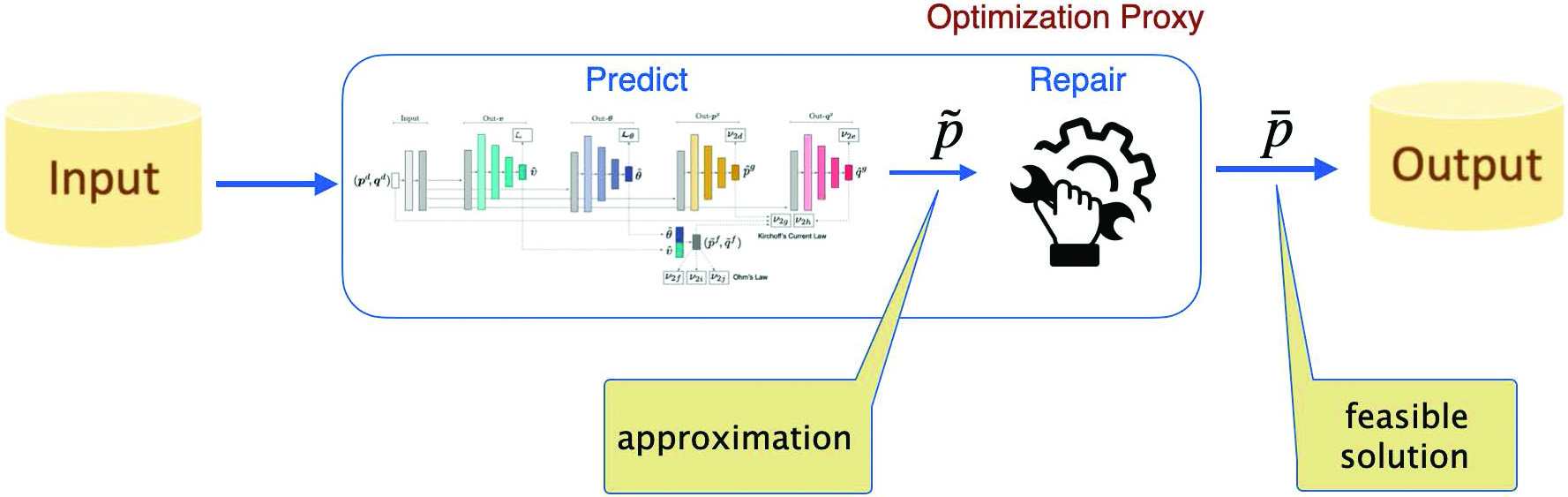
Optimization proxies seek to overcome this difficulty by combining a predictive component (typically a deep neural network) that produces an approximation \(\tilde{\mathbf{p}}\) with a repair layer that transforms \(\tilde{\mathbf{p}}\) into a feasible solution \(\overline{\mathbf{p}}\) (see Figure 1). In a first approximation, the repair layer acts as a projection of \(\tilde{\mathbf{p}}\) into the feasible space of the optimization problem. In practice, however, it is often preferable to design dedicated repair layers that ensure fast training and inference times.
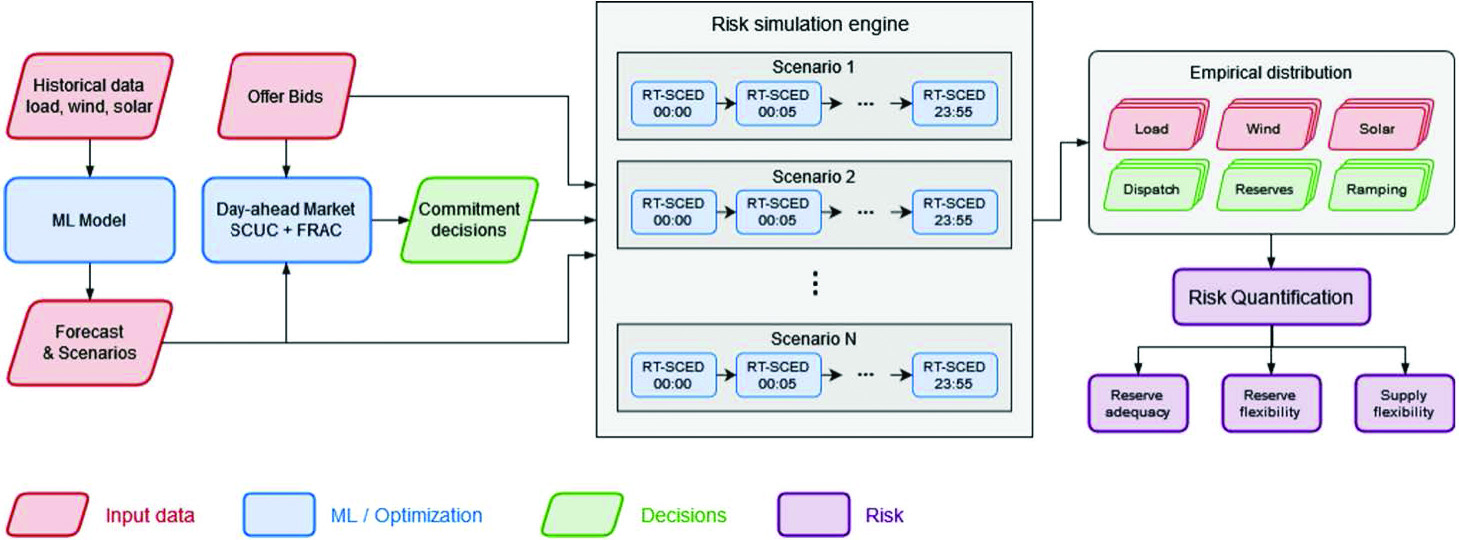
Optimization proxies have the potential to transform various classes of applications through orders-of-magnitude improvements in efficiency. For example, consider the real-time risk assessment framework in Figure 2, which runs a collection of Monte Carlo scenarios. Each scenario necessitates 288 optimizations, which equates to one every five minutes over a 24-hour period. This process takes about 15 minutes. But when we replace each optimization with its proxy, we can evaluate every scenario in roughly five seconds [3]. Other possible applications include dashboards for tactical planning and operations in areas such as energy distribution, supply chains, and manufacturing. It may also be possible to deploy models with much higher fidelity, which would shift most of the computational burden offline during training. Here, I describe some of the science and engineering concepts that underly optimization proxies and highlight research in trustworthy optimization proxies that guarantee feasibility and quality.
Differentiable Programming
The repair layers of optimization proxies rely on differential programming: the use of dynamic computational graphs that can be automatically and transparently differentiated. Consider a simplified version of the economic dispatch that is utilized by the Independent System Operators (ISOs) in the U.S.:
\[\begin{align} \min \limits_{\mathbf{p, r}, \xi_\textrm{th}} \quad &c(\mathbf{p}) + M_\textrm{th} \| \xi_\textrm{th} \|_{1} \tag{2a} \\ \textrm{s.t.} \quad &\mathbf{e}^{\top}\mathbf{p} = \mathbf{e}^{\top} \mathbf{d}, \tag{2b} \\ &\mathbf{0} \leq \mathbf{p} \leq \overline{\mathbf{p},} \tag{2c} \\ &\underline{\mathbf{f}} -\xi_\textrm{th} \leq \Phi (\mathbf{p} - \mathbf{d}) \leq \mathbf{\overline{f}} +\xi_\textrm{th}, \tag{2d} \\ &\xi_\textrm{th} \geq \mathbf{0}. \tag{2e} \end{align}\]
ISOs solve this fundamental optimization problem to balance generation and demand in electricity grids while also accounting for reserve constraints and thermal limits. Constraint \((2\textrm{b})\) captures the global power balance, \((2\textrm{c})\) enforces minimum and maximum limits on each generator’s active power, and \((2\textrm{d})\) uses a power transfer distribution factor to express the thermal constraints on every branch. The thermal constraints in U.S. electricity markets are traditionally soft; they can be violated, but doing so incurs a high cost [5, 6]. Since it is a regression, the approximation \(\tilde{\mathbf{p}}\) in the proxy does not satisfy the power balance constraint. However, the repair layer can utilize control systems concepts to scale the generators proportionally and obtain a feasible solution \(\overline{\mathbf{p}}\):
\[\overline{\mathbf{p}} = \begin{cases} (1-\zeta^{\uparrow})\tilde{\mathbf{p}} + \zeta^\uparrow\overline{\mathbf{g}} \quad \textrm{if} \enspace \mathbf{1}^{\top}\tilde{\mathbf{p}}<\mathbf{1}^{\top}\mathbf{d}, \\
(1-\zeta^{\downarrow})\tilde{\mathbf{p}} + \zeta^\downarrow\underline{\mathbf{g}} \quad \textrm{otherwise,} \end{cases} \tag3\]
where \(\zeta^{\uparrow}\) and \(\zeta^{\downarrow}\) are defined as
\[\zeta^{\uparrow} = \frac{\mathbf{1}^{\top}\mathbf{d}-\mathbf{1}^{\top}\tilde{\mathbf{p}}}{\mathbf{1}^{\top}\overline{\mathbf{g}}-\mathbf{1}^{\top}\tilde{\mathbf{p}}}, \qquad \qquad \zeta^{\downarrow} = \frac{\mathbf{1}^{\top}\tilde{\mathbf{p}}-\mathbf{1}^{\top}\mathbf{d}}{\mathbf{1}^{\top}\tilde{\mathbf{p}}-\mathbf{1}^{\top}\underline{\mathbf{g}}}. \tag4\]
This layer is differentiable almost everywhere, which means that we can naturally integrate it into the training process of the ML model. This type of overall architecture guarantees feasibility during training and inference and can generate near-optimal feasibility for economic dispatch problems in mere milliseconds [3].
Self-supervised Optimization Proxies
One appealing feature of optimization proxies is the possibility of self-supervised learning: training proxies without labeled data [4, 8]. For instance, self-supervised learning is possible for the aforementioned economic dispatch if we use the original objective function as the loss function to train the optimization proxy \(P_\theta\), i.e., \(\mathcal{L}( \mathbf{y} | \theta) =f_{\mathbf{x}}(\mathbf{y})\). Stochastic gradient descent could then learn the parameters \(\theta\). Self-supervised learning thus removes the need to solve the optimization problems that are specified by the dataset \(\mathcal{D}\).
Dual Feasible Solutions
An ideal outcome in optimization practice is a pair of primal and dual solutions with a small duality gap. Another attractive feature of optimization proxies is their ability to find these dual feasible solutions for many convex optimization problems that arise in engineering. Consider the following linear program and its dual:
\[\begin{align} \min \qquad &c^T \mathbf{x} & \qquad \qquad \qquad \min \qquad &b^T \mathbf{y} \\ s.t. \qquad &A \mathbf{x} \geq b & \qquad \qquad \qquad s.t. \qquad &\mathbf{y} A - \lambda + \gamma = c \\ &l \leq \mathbf{x} \leq u & \qquad \qquad \qquad &\mathbf{y}, \lambda, \gamma \geq 0. \end{align}\]
The formulation of the primal optimization reflects the fact that decision variables have lower and upper bounds in many engineering problems. As a result, it is relatively easy to restore feasibility in the dual space. Indeed, the optimization proxy for the dual optimization can first predict \(\mathbf{y}\) and then use \(\lambda\) and \(\gamma\) to determine a dual feasible solution. One study applied the same idea to the second-order cone relaxation of the alternating current power flow equations, wherein the reconstruction utilizes properties of the optimal solutions [9]. Experimental results confirm that the ensuing proxies can find near-optimal dual feasible solutions.
Primal-dual Learning
Optimization proxies also offer a unique opportunity for researchers to adapt traditional optimization algorithms to the learning context. Consider the constrained optimization problem
\[\min \limits_{\mathbf{y}} f_{\mathbf{x}}(\mathbf{y}) \enspace \mbox{ subject to } \enspace \mathbf{h}_{\mathbf{x}}(\mathbf{y}) = 0, \tag5\]
where \(\mathbf{x}\) represents instance parameters that determine the objective function \(f_\mathbf{x}\) and equality constraint \(\mathbf{h}_\mathbf{x}\).
Primal-dual learning (PDL) [8] jointly learns two neural networks: (i) a primal neural network \(P_{\theta}\) that learns the input/output mapping of the unconstrained optimizations of the augmented Lagrangian method (ALM), and (ii) a dual network \(\boldsymbol{\lambda}\) that learns the dual updates. At each iteration, the primal learning step updates the parameters \(\theta\) of the primal network while keeping the dual network \(D_\phi\) fixed. After primal learning is complete, PDL applies a dual learning step that updates the parameters \(\phi\) of the dual network \(D_\phi\). Training the primal network involves the loss function
\[\mathcal{L}_{\textrm{p}}(\mathbf{y} | \boldsymbol{\lambda}, \rho) = f_{\mathbf{x}}(\mathbf{y}) + \boldsymbol{\lambda}^T\mathbf{h}_\mathbf{x}(\mathbf{y}) + \frac{\rho}{2}\mathbf{1}^{\top}\nu(\mathbf{h}_\mathbf{x}(\mathbf{y})), \]
which is the direct counterpart of the ALM unconstrained optimization; here, \(\rho\) is a penalty coefficient and \(\boldsymbol{\lambda}\) represents the Lagrangian multiplier approximations. The dual learning training uses the loss function
\[\mathcal{L}_{\textrm{d}}(\boldsymbol{\lambda} | \mathbf{y}, \boldsymbol{\lambda}_k, \rho) = \| \boldsymbol{\lambda} -(\boldsymbol{\lambda}_k + \rho \mathbf{h}_\mathbf{x}(\mathbf{y}))\|,\]
which is the direct counterpart of the update rule for the Lagrangian multipliers of the ALM. These two steps—the training of the primal and dual networks—are iterated in sequence until convergence. Note that PDL is self-supervised and does not require labeled data. Researchers have applied PDL to preventive security-constrained optimal power flow problems with automatic primary response [7] — an application that even state-of-the-art optimization cannot solve. This work highlights optimization proxies’ ability to deploy optimization models that would otherwise be too complex to meet real-time requirements.
Convex Optimization Proxies
Optimization models often appear as components in other types of optimization models, including decomposition techniques, bilevel optimization, and stochastic optimization. Can optimization proxies be similarly compositional? While we can encode a neural network with rectified linear unit (ReLU) activation functions as a mixed-integer program (MIP), the resulting non-convexities and computational challenges make this tactic undesirable. An intriguing alternative is the use of convex neural networks — or more precisely, input-convex neural networks. A neural network with ReLU activation functions computes a convex function if all of its weights are nonnegative. An input-convex neural network generalizes this idea by introducing a first layer whose weights are unconstrained and adding skip connections to all other “convex” layers. More precisely, the \(k\)th layer of an input-convex neural network takes the form
\[\mathbf{x}^{k} = h^{k}(\mathbf{x}^{k-1}) = \textrm{ReLU}(W^{k} \mathbf{x}^{k-1} + H^{k} \mathbf{x}^{0} + d^{k}). \tag6\]
Here, \(\mathbf{x}^{k}\) and \(\mathbf{x}^{k-1}\) denote the outputs of layer \(k\) and \(k-1\), \(\mathbf{x}^{0}\) signifies the input of the iterative convolutional neural network (ICNN), \(d^{k}\) is the bias vector, and \(W^k\) and \(H^k\) are weight matrices. Skip connections feed the ICNN input \(\mathbf{x}^{0}\) to each layer. The coefficients of \(W^k\) are nonnegative, whereas \(H^k\) may take positive or negative values without affecting convexity [1]. Once it is trained, the input-convex neural network provides a function and gradient with respect to its inputs — thereby meeting the requirements of multiple applications. Input-convex neural networks can approximate the objective value of alternating current optimal power flow, its second-order cone relaxation, and its direct current approximation with high accuracy, which reveals many promising avenues for practical implementation [10].
Applications
Optimization proxies can find utility in a variety of applications, including energy systems, mobility engineering, transportation, and supply chains. In mobility settings, the use of optimization proxies within a model-predictive control framework can help relocate vehicles in an ideal manner. Reinforcement learning fine-trains these proxies to capture long-term effects, and the repair layers use linear programming (transportation) models that are solvable in polynomial time. In transportation and supply chain contexts, proxies approximate complex MIPs with poor linear relaxations, resulting in an order-of-magnitude reduction in MIP size for real-time solutions. And as evidenced by this article, researchers have studied proxies for energy systems in significant depth.
Pascal Van Hentenryck delivered an invited lecture on this topic at the 10th International Congress on Industrial and Applied Mathematics, which took place in Tokyo, Japan, last year.
References
[1] Amos, B., Xu, L., & Kolter, J.Z. (2017). Input convex neural networks. In Proceedings of the 34th international conference on machine learning (PMLR 70) (pp. 146-155). Sydney, Australia: Proceedings of Machine Learning Research.
[2] Bengio, Y., Lodi, A., & Prouvost, A. (2021). Machine learning for combinatorial optimization: A methodological tour d’horizon. Eur. J. Oper. Res., 290(2), 405-421.
[3] Chen, W., Tanneau, M., & Van Hentenryck, P. (2024). End-to-end feasible optimization proxies for large-scale economic dispatch. IEEE Trans. Power Syst. To appear.
[4] Donti, P.L., Rolnick, D., & Kolter, J.Z. (2021). DC3: A learning method for optimization with hard constraints. In The ninth international conference on learning representations (ICLR 2021).
[5] Ma, X., Song, H., Hong, M., Wan, J., Chen, Y., & Zak, E. (2009). The security-constrained commitment and dispatch for Midwest ISO day-ahead co-optimized energy and ancillary service market. In 2009 IEEE power and energy society general meeting (pp. 1-8). Calgary, Canada: Institute of Electrical and Electronics Engineers.
[6] Midcontinent Independent System Operator. (2022). Attachment D – Real-time energy and operating reserve market software formulations and business logic. In Business practices manual: Energy and operating reserve markets. Carmel, IN: Midcontinent Independent System Operator.
[7] Park, S., & Van Hentenryck, P. (2023). Self-supervised learning for large-scale preventive security constrained DC optimal power flow. Preprint, arXiv:2311.18072.
[8] Park, S., & Van Hentenryck, P. (2023). Self-supervised primal-dual learning for constrained optimization. In Proceedings of the 37th AAAI conference on artificial intelligence (pp. 4052-4060). Washington, D.C.: Association for the Advancement of Artificial Intelligence.
[9] Qiu, G., Tanneau, M., & Van Hentenryck, P. (2024). Dual conic proxies for AC optimal power flow. In Proceedings of the 23rd power systems computation conference (PSCC2024). Paris, France.
[10] Rosemberg, A., Tanneau, M., Fanzeres, B., Garcia, J., & Van Hentenryck, P. (2023). Learning optimal power flow value functions with input-convex neural networks. Preprint, arXiv:2310.04605.
[11] Wright, S.J., & Recht, B. (2022). Optimization for data analysis. Cambridge, U.K.: Cambridge University Press.
About the Author
Pascal Van Hentenryck
A. Russell Chandler III Chair, Georgia Institute of Technology
Pascal Van Hentenryck is the A. Russell Chandler III Chair and a professor of industrial and systems engineering at the Georgia Institute of Technology. He is also director of the National Science Foundation’s Artificial Intelligence (AI) Institute for Advances in Optimization, which seeks to fuse AI and optimization

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
