
Geotechnical Risk Assessment: Overcoming Small Data Challenges With Language Models
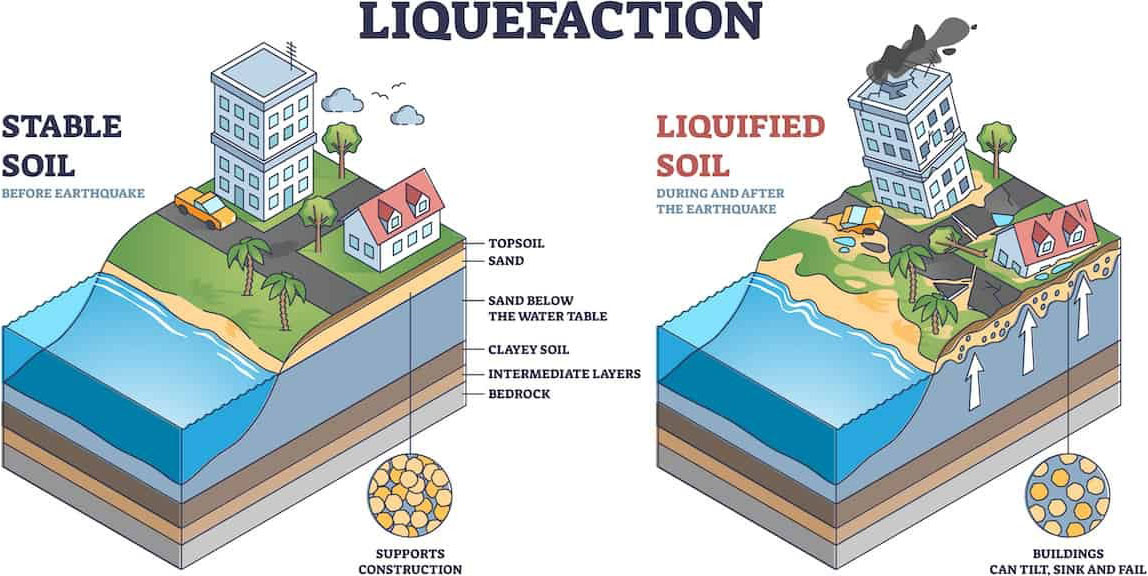
Soil liquefaction during seismic events poses catastrophic risks to infrastructure (see Figure 1). Yet despite the urgent need, the accurate prediction of liquefaction remains an ongoing geotechnical engineering challenge [1]. Traditional machine learning (ML) approaches often fail in the presence of sparse, heterogeneous datasets — a common reality in geoscience applications. Here, we explore recent advances in language model (LM) architectures that bridge the gap between structured geotechnical data and contextual reasoning, ultimately redefining predictive capabilities.
Fundamental Limitations of Conventional Machine Learning in Geotechnical Applications
Geotechnical risk assessment relies on the interpretation of multidimensional parameters: seismic acceleration profiles, soil saturation levels, shear strength metrics, standard penetration test (SPT-N) values, and other aspects that pertain to the dynamic case. Conventional ML models—such as gradient-boosted trees and support vector machines—struggle with these datasets due to two core issues:
- Data Sparsity: Site-specific geotechnical investigations yield limited samples (often fewer than 1,000 data points per project), thus creating high-dimensional feature spaces that worsen overfitting. Additionally, national security concerns often preclude countries from sharing geotechnical investigative data.
- Contextual Blind Spots: Tabular representations fail to capture latent relationships between parameters (e.g., the modulation of pore pressure buildup by grain size distribution during cyclic loading).
Benchmark studies reveal that tree-based models exhibit up to 30 percent accuracy degradation when training on datasets with fewer than 10,000 samples, particularly in heterogeneous geological settings [3]. Therefore, the results tend to include statistical hallucinations and yield no tangible outcomes.
Language Models as Interpretive Frameworks for Structured Data
The paradigm shift lies in the reimagination of geotechnical parameters as semantic narratives. LMs can convert tabular entries into structured textual descriptions (e.g., a 12-meter sandy stratum where SPT-N=18, saturated under 0.35 g peak ground acceleration), allowing them to apply their pretrained capacity for contextual reasoning to geotechnical domains. Essentially, they turn tabular data into natural language (i.e., English) that describes the situation in geotechnical terms [2]. Key advantages of this approach include the following:
- Cross-parameter Attention: Transformer architectures use self-attention layers to natively model interactions between disparate variables (e.g., seismic inputs versus soil composition), bypassing manual feature engineering [4].
- Few-shot Generalization: Pretrained LMs adapt to small datasets by leveraging linguistic patterns from broader corpora (e.g., geological reports or technical manuals).
- Uncertainty Quantification: Probabilistic outputs from LMs naturally align with risk assessment frameworks, providing confidence intervals for liquefaction potential.
From Tables to Text: Encoding Geotechnical Semantics
The efficacy of LMs hinges on the preservation of domain-specific semantics during data transformation. In addition to proprietary methods, the following open techniques are available:
- Template-based Serialization: Mapping soil profiles to standardized sentence structures (e.g., layer [depth]: [soil type] with [percent moisture] saturation, [density] g/cm³).
- Embedding Fine-tuning: Retraining token embeddings on geotechnical lexicons (e.g., liquefaction susceptibility index or cyclic stress ratio) to enhance model comprehension.
- Metadata Augmentation: Appending contextual clues (e.g., regional seismicity history or depositional environment) as textual annotations.
These open approaches reduce reliance on expansive datasets by treating each site investigation as a unique "document" within the LM's corpus.
Case Study: Risk Prediction in Seismic Zones
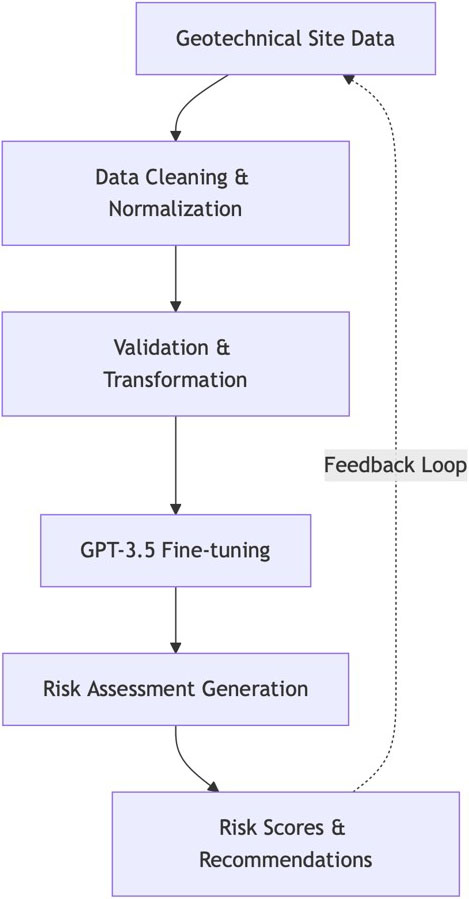
We can use a hypothetical deployment in a high-risk region to illustrate the methodology (see Figure 2). The steps are as follows:
- Input: 500 site investigations (SPT-N, soil gradation, groundwater levels, etc.) that we convert to natural language entries.
- Processing: By correlating subtle text patterns (e.g., "poorly graded sands" with "rapid pore pressure rise"), our LM identifies high-risk zones that conventional models miss.
- Outcome: 22 percent higher accuracy than gradient-boosted models, with heatmaps that highlight spatially variable risk.
Such a system enables dynamic updates—which integrate real-time sensor data from piezometers and accelerometers—to refine predictions as new seismic events unfold.
The integration of LMs into the field of geotechnical engineering represents more than a technical advancement — it forms a conceptual bridge between data-driven artificial intelligence tools and the nuanced realities of Earth systems. By transcending the limitations of small datasets through semantic reasoning, these approaches empower engineers to build resilient infrastructure amid growing climatic and seismic uncertainties. As the field evolves, collaborative frameworks that unite civil engineers, data scientists, and policymakers will help to translate algorithmic insights into actionable safeguards for vulnerable communities.
For more information about this project, please visit the Geoliquefy website.
References
[1] Abbasimaedeh, P. (2024). Soil liquefaction in seismic events: Pioneering predictive models using machine learning and advanced regression techniques. Environ. Earth Sci., 83(7), 189.
[2] Borisov, V., Seßler, K., Leemann, T., Pawelczyk, M., & Kasneci, G. (2022). Language models are realistic tabular data generators. Preprint, arXiv:2210.06280.
[3] Grinsztajn, L., Oyallon, E., & Varoquaux, G. (2022). Why do tree-based models still outperform deep learning on typical tabular data? In NIPS'22: Proceedings of the 36th international conference on neural information processing systems (pp. 507-520). New Orleans, LA: Curran Associates, Inc.
[4] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., ... Polosukhin, I. (2017). Attention is all you need. In NIPS’17: Proceedings of the 31st international conference on neural information processing systems (pp. 6000-6010). Long Beach, CA: Curran Associates, Inc.
About the Authors
Achyut Tiwari
Founder, Geoliquefy
Achyut Tiwari is the founder of Geoliquefy, a venture that explores artificial intelligence applications in soil liquefaction and geotechnics. He is also a data scientist at Tata Consultancy Services in India, where his research combines machine learning and dynamical systems to apply computational methodologies in bioinformatics and other fields of engineering. Tiwari is the founding president of the Jaypee University of Information Technology SIAM Student Chapter.

Ashok Kumar Gupta
Professor, Jaypee University of Information Technology
Ashok Kumar Gupta is a professor of civil engineering and Dean of Academics and Research at Jaypee University of Information Technology. He also serves as chief scientific advisor of Geoliquefy. Gupta has more than 38 years of experience in teaching and research and received his Ph.D. from the Indian Institute of Technology Delhi.

Saurabh Rawat
Associate professor, Jaypee University of Information Technology
Saurabh Rawat is an associate professor of civil engineering at Jaypee University of Information Technology (JUIT). He also serves as an advisor at Geoliquefy on geotechnical problems. Rawat, who received his Ph.D. from JUIT, has more than 12 years of experience in teaching and research and three published patents to his name.

Related Reading



Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
