
Learning Oscillatory Navier-Stokes Flows and Causal Linear Operators with Deep Neural Network Algorithms
Much of the lively research activity in machine learning (ML) for scientific computing stems from the power of deep neural networks (DNNs), which are known for their expressibility and effective handling of high-dimensional data. ML has revolutionized tasks such as natural language processing, image and speech recognition, and recommender systems, while scientific computing contributes to the solution of many complex mathematical and physical problems in areas like physics, chemistry, biology, and engineering.
By combining ML and scientific computing, researchers and engineers can leverage ML’s strengths to tackle challenging problems that were previously unsolvable. ML techniques can help analyze large amounts of high-dimensional data from simulations and experiments in scientific computing, thus providing insights that would otherwise be difficult to obtain. On the other hand, researchers can use scientific computing to design and optimize complex ML models, ultimately yielding more accurate and efficient algorithms.
ML’s introduction into scientific computing has already led to breakthroughs in various fields, including drug discovery, climate modeling, and materials science. As ML and scientific computing continue to advance, the opportunities for further integration and cross-fertilization will be boundless.
Here, we will explore the utilization of ML techniques in the realm of computational mathematics. The first project that we will describe uses neural networks (NNs) to address nonlinear problems with highly oscillatory solutions, while the second project employs NNs to approximate operators that represent causal physical systems.
Linearized Learning to Solve Nonlinear Flow Problems with Oscillatory Solutions
Achieving high accuracy in deep learning models often requires a large amount of data and computation, which can be challenging in certain scientific fields. Partial differential equations (PDEs) and their associated initial or boundary conditions can potentially serve as a regularization technique for ML models [7].
In this project, we utilized NNs to learn the solutions of incompressible stationary Navier-Stokes flows with Dirichlet boundary conditions in a complex domain [4]:
\[\begin{cases} - \nu \Delta \boldsymbol{u} + \left( \boldsymbol{u}\cdot \nabla \right)\boldsymbol{u} + \nabla p = \boldsymbol{f}, &\boldsymbol{x} \in \Omega,\\ \nabla \cdot \boldsymbol{u} = 0, &\boldsymbol{x} \in \Omega, \\ \boldsymbol{u}\left( \boldsymbol{x} \right) = \boldsymbol{g}\left( \boldsymbol{x} \right), &\boldsymbol{x} \in \partial \Omega. \end{cases}\tag1\]
By using the equation residuals and the boundary or initial conditions as regularization in the training loss, the NN serves as an adaptive basis that can provide an effective alternative to the basis function in finite element methods.
Due to the presence of nonlinear terms, training a NN that is regularized with the first-order form of stationary Navier-Stokes flow is insufficient for learning highly oscillatory solutions. However, a previous study found that the solution of the corresponding linearized Navier-Stokes equation—that is, the Stokes equation—can be learned effectively [8]. To improve the learning process for the solution of nonlinear Navier-Stokes equations, researchers have proposed several linearized learning schemes that can be integrated with the training process to alleviate the difficulties that stem from the nonlinearities.
An example of one such linearized learning scheme is as follows:
\[-\nu \Delta \boldsymbol{u}_{\theta} + (\boldsymbol{u}^{*}_{\theta}\cdot \nabla)\boldsymbol{u}_{\theta} + \nabla p_{\theta} = \boldsymbol{f},\\ \Delta p_{\theta} + 2(-u_{x}^{}v_{y}^{}+ u_{y}^{}v_{x}^{}) = \nabla\cdot \boldsymbol{f}.\tag2\]
Here, \(\boldsymbol{u}^{*}_{\theta}\) represents the trained velocity and \(\boldsymbol{u}_{\theta}\) and \(p_{\theta}\) are the NNs that are being trained. The pressure \(p_{\theta}\) is further regularized by a Poisson equation that is given by the incompressibility of \(\boldsymbol{u}\), \(\nabla \cdot \boldsymbol{u}_{\theta} = 0\).
The corresponding loss to train the NN takes the form
\[\textrm{L}_{\boldsymbol{u}} = \textrm{R}_{\boldsymbol{u}} + \alpha \textrm{B}_{\boldsymbol{u}} +\beta\textrm{R}_{p} + \gamma \textrm{I}_{\boldsymbol{u}}, \\\]\[\textrm{R}_{\boldsymbol{u}} =\left\|-\nu \Delta \boldsymbol{u}_{\theta} + (\boldsymbol{u}^{*}_{\theta}\cdot \nabla)\boldsymbol{u}_{\theta} + \nabla p_{\theta} - \boldsymbol{f}\right\|_{2,X}^{2},\\\] \[\textrm{R}_{p} = \left\| \Delta p + 2(-u_{x}^{}v_{y}^{}+ u_{y}^{}v_{x}^{}) - \nabla\cdot \boldsymbol{f}\right\|_{2,M}^{2} , \\\] \[\textrm{B}_{\boldsymbol{u}} = \int_{\partial \Omega}\left( \boldsymbol{u}^{} - \boldsymbol{g} \right)^2dS,\\\] \[\textrm{I}_{\boldsymbol{u}} = \int_{\Omega} \left( \nabla \cdot \boldsymbol{u} - 0 \right)^2 d\boldsymbol{x}.\tag3\]
where \(\alpha\), \(\beta\), and \(\gamma\) are penalty terms.

The algorithm in Figure 1 outlines the NN learning process. Once the loss \(L\) is less than or equal to the threshold \(\gamma \tau\), the parameters of \(\mathbf{u}_{\theta}^{i}\) will be copied to \(\mathbf{u}^{*}_{\theta}\) (though we note that the parameters of \(\mathbf{u}^{*}_{\theta}\) are never updated by the Adam algorithm). The number of epochs \(c\) before updating the fixed (linearized) term is then an adjustable hyperparameter.
We propose several similar linearized schemes in our work [4]. In essence, we linearize the stationary Navier-Stokes equation by substituting one of the components in its nonlinear term with the learned solutions; the learned solutions will then converge to the exact solution as the training progresses.
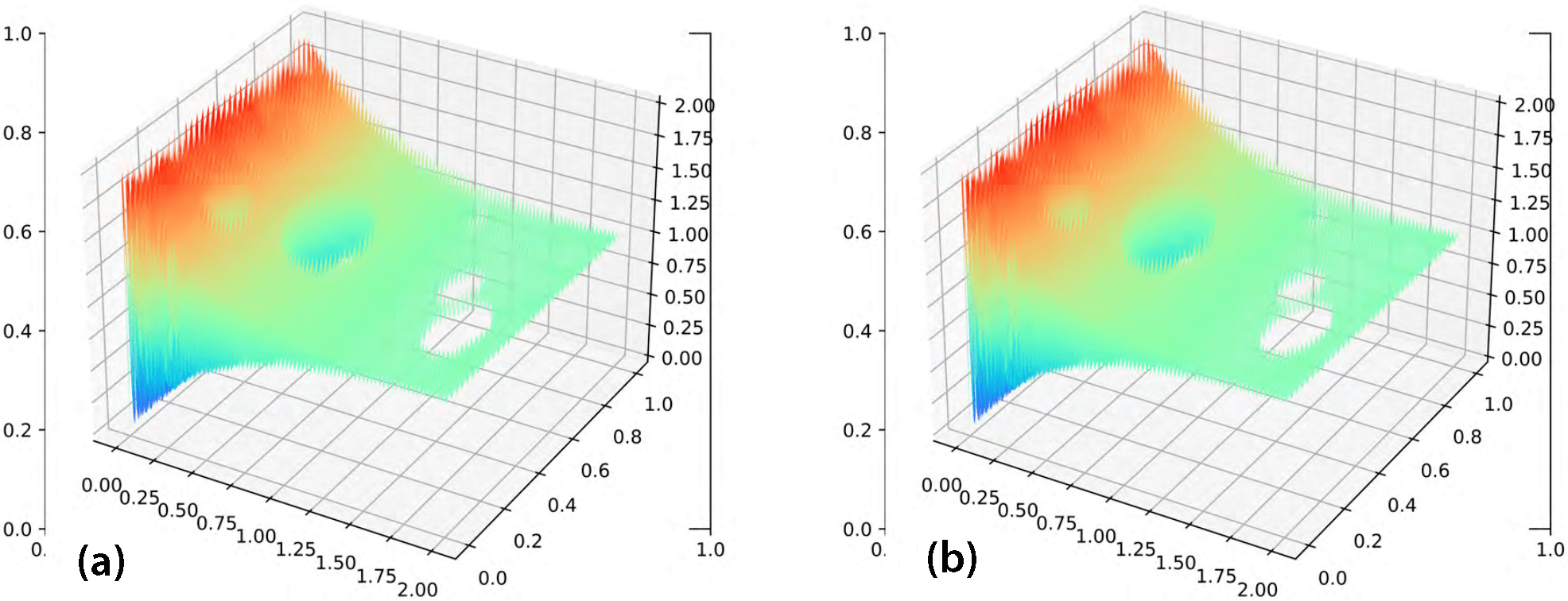
Recent research has identified a spectral bias phenomenon of NNs called the frequency principle [9], wherein the networks tend to capture low-frequency components prior to high-frequency components during training. Several studies have attempted to remedy this frequency bias by proposing modifications to NNs, including PhaseDNN [1] and the multiscale DNN [5]. The fully connected NN will experience spectral bias for problems with oscillatory source terms, despite the incorporation of the linearized learning scheme. However, applying the multiscale NN framework mitigates this spectral bias. Figure 2 displays the results for the velocity field that is predicted by multiscale NNs and produced by the oscillating force term.
The success of linearized learning schemes for stationary Navier-Stokes equations suggests that extending the linearizing framework to other nonlinear differential equations may provide a new approach for NNs to solve nonlinear equations with oscillatory solutions, particularly in high-dimensional problems. The convergence theories that underlie these linearizing schemes are currently unresolved.
Learning Operators Represent Causal Physical Systems
The research that we have discussed thus far targets the use of one NN to solve a given equation. Yet in many scientific and engineering applications, the boundary conditions, initial conditions, or coefficients in the equations may vary; in these cases, it is therefore necessary to retrain the NNs. One solution is to learn operators between physical quantities that are defined in function spaces [2, 6]. This framework has found many applications in both forward and inverse problems in scientific and engineering computations. For example, consider wave scattering in inhomogeneous or random media. In this case, the mapping between the media’s physical properties—which one can model as a random field—and the wave field is a nonlinear operator. This operator represents some of the most challenging computational tasks in medical imaging and geophysical and seismic problems.
A specific example arises from earthquake safety studies of buildings and structures, as structures’ responses to seismic ground accelerations give rise to a causal operator between spaces of highly oscillatory temporal signals [3]. The most intuitive idea is to incorporate the network that can handle the aforementioned oscillating signals as part of the NNs that learn the operators. However, the NN may struggle to predict the test case—despite showing a decrease in training loss that indicates the NN’s convergence—which might hinder the application of this intuitive idea. To address this issue, we identified causality and convolution form as crucial factors and incorporated them into our framework. Given input signal \(\ddot{u}_{g}\), we approximate the operator \(\mathcal{R}: \ddot{u}_{g} \mapsto x\) with
\[\mathcal{R}(\ddot{u}_{g})(t) \sim \sum_{k=1}^{N}c_{k}\underbrace{\sum_{i=1}^{M}\sigma_{b}\left( \sum_{j=1}^{\left\lfloor \frac{t}{h}\right\rfloor }W_{i,\left\lfloor \frac{T}{h} \right\rfloor -\left\lfloor \frac{t}{h}\right\rfloor +j}^{k}\ddot{u}_{g}\left( s_{j}\right)+\sum_{j=\left\lfloor \frac{t}{h}\right\rfloor }^{\left\lfloor \frac{T}{h}\right\rfloor -1 }W_{i,\left\lfloor \frac{T}{h} \right\rfloor -j}^{k} 0 + B_{i}^{k} \right)}_{B_k} \underbrace{\sigma_{t}\left( \boldsymbol{w}_{k} t+b_{k}\right)}_{T_k}.\tag4\]
Here, positive integers \(M\), \(N\), \(m\) and equal-spaced points \(\left\{t_{j} \right\}_{j=1}^{m} \in [0,T]\) with real constants \(c_{i}^{k}\), \(W_{ij}^{k}\), \(B_{i}^{k} \in \mathbb{R}\), \(i=1,\ldots, M\), \(j=1,\ldots, m\), \(\left\{\boldsymbol{w}_{k}\right\}_{k=1}^{N} \in \mathbb{R}\), \(\left\{ b_{k} \right\}_{k=1}^{N} \in \mathbb{R}\) are all independent to the continuous functions \(\ddot{u}_{g} \in C[0,T]\) and \(t\). As evidenced in \((4)\), only the information from \(\ddot{u}_{g}\) to time \(t\) is needed to predict the building response at time \(t\). Figure 3 depicts our proposed Causality-DeepONet’s predictions of building response to seismic excitations.
The current operator learning scheme for operators with causality has shown promising results. To further improve the performance and expand the approach’s applicability, we plan to build upon the successes of our previous projects and incorporate specific differential equations as additional regularization terms. We will also investigate the theoretical foundations of this technique, specifically for the proposed Causality-DeepONet. To do so, we will explore convergence properties, generalization abilities, and potential improvements to the training algorithm.
In addition, we aim to extend this framework to the more complex differential equation systems and time-dependent PDEs that often appear in physics, engineering, and other scientific domains. NNs’ ability to learn and approximate complex functions and operators makes them a promising tool for tackling these challenging problems.
![<strong>Figure 3.</strong> The worst predictions in the testing dataset for the Causality-DeepONet (relative L2 error: 0.0042). <strong>3a.</strong> The amplitude of the prediction and true response in the Fourier domain. <strong>3b.</strong> The prediction and true response. <strong>3c.</strong> The corresponding input signals. <strong>3d.</strong> The relative error. Figure courtesy of [3].](/media/xhndkws4/figure3_updated.jpg)
Conclusions
The combination of deep learning and scientific computing has shown great potential to address challenging problems in scientific fields. We incorporated the linearization of nonlinear PDEs when training NNs to learn the PDE solutions, thereby achieving faster and more accurate results. The incorporation of specific domain knowledge—such as causality and convolution structure—into the operator learning process can also yield better predictions, even without large data.
Nevertheless, many open questions remain in terms of understanding the mathematical foundations of our proposed methods and ensuring their reliability in real-world applications. Further research and development are necessary to fully realize the potential of ML for scientific computing. With additional progress, this field is expected to continue advancing our knowledge and ability to solve complex problems in science and engineering.
Lizuo Liu delivered a minisymposium presentation on this research at the 2022 SIAM Conference on Mathematics of Data Science (MDS22), which took place in San Diego, Ca., last year. He received funding to attend MDS22 through a SIAM Student Travel Award. To learn more about Student Travel Awards and submit an application, visit the online page.
SIAM Student Travel Awards are made possible in part by the generous support of our community. To make a gift to the Student Travel Fund, visit the SIAM website.
Acknowledgments: We acknowledge collaborations with Bo Wang of Hunan Normal University in China and Kamaljyoti Nath of Brown University, as well as helpful discussions with George Karniadakis of Brown University. This research is funded by the National Science Foundation (grant number DMS-2207449). The computations were performed on the high-performance computing facilities at Southern Methodist University.
References
[1] Cai, W., Li, X., & Liu, L. (2020). A phase shift deep neural network for high frequency approximation and wave problems. SIAM J. Sci. Comput., 42(5), A3285-A3312.
[2] Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., & Anandkumar, A. (2020). Fourier neural operator for parametric partial differential equations. In Ninth international conference on learning representations (ICLR 2021).
[3] Liu, L., Nath, K., & Cai, W. (2023). A causality-DeepONet for causal responses of linear dynamical systems. Preprint, arXiv:2209.08397.
[4] Liu, L., Wang, B., & Cai, W. (2023). Linearized learning with multiscale deep neural networks for stationary Navier-Stokes equations with oscillatory solutions. East Asian J. Appl. Math., 13(3), 740-758.
[5] Liu, Z., Cai, W., & Xu, Z.-Q.J. (2020). Multi-scale deep neural network (mscalednn) for solving Poisson-Boltzmann equation in complex domains. Commun. Comput. Phys., 28(5), 1970-2001.
[6] Lu, L., Jin, P., Pang, G., Zhang, Z., & Karniadakis, G.E. (2021). Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell., 3(3), 218-229.
[7] Raissi, M., Perdikaris, P., & Karniadakis, G.E. (2019). Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys., 378, 686-707.
[8] Wang, B., Zhang, W., & Cai, W. (2020). Multiscale deep neural network (MscaleDNN) methods for oscillatory stokes flows in complex domains. Commun. Comput. Phys., 28(5), 2139-2157.
[9] Xu, Z.-Q.J., Zhang, Y., Luo, T., Xiao, Y., & Ma, Z. (2020). Frequency principle: Fourier analysis sheds light on deep neural networks. Commun. Comput. Phys., 28(5), 1746-1767.
About the Authors
Lizuo Liu
Ph.D. Student, Southern Methodist University
Lizuo Liu is a Ph.D. student in the Department of Mathematics at Southern Methodist University. His research interests lie in machine learning for scientific algorithms.

Wei Cai
Clements Chair of Applied Mathematics, Southern Methodist University
Wei Cai is the Clements Chair of Applied Mathematics in the Department of Mathematics at Southern Methodist University. His research interests lie in machine learning for scientific computing, stochastic algorithms, computational electromagnetics and quantum transport, and computational biology.

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
