
Multi-agent Simulations and Vaccine Allocation Strategies
Epidemic science pertains to the development of models, technologies, and decision support tools to understand and control the spread of disease. This area of research is especially critical as the COVID-19 pandemic continues to cause significant social, economic, political, and health-related impacts across the globe. In a previous article, we outlined an epidemiological approach that is rooted in network science and data-driven modeling. Here we discuss the challenges of such an approach’s implementation during an evolving pandemic in the context of the vaccine prioritization problem, and outline our recent efforts to develop operational models that support policymaking.
We focus on networked models, which consider epidemic spread on an undirected social interaction network \(G(V,E)\) over a population \(V\); each edge \(e=(u,v) \in E\) implies that individuals (also called nodes) \(u,v \in V\) interact. The susceptible-infected-recovered (SIR) model on graph \(G\) represents a dynamical process wherein each node is in either an S, I, or R state. Infection can potentially spread from \(u\) to \(v\) along edge \(e= (u,v)\), with a probability of \(\beta(e,t)\) at time \(t\) after \(u\) becomes infected — conditional on node \(v\) remaining uninfected until time \(t\). \(I(t)\) denotes the set of nodes that become infected at \(t\).
The basic vaccine allocation problem involves deciding who to vaccinate and when to do so. The objective is to minimize the number of infections, hospitalizations, or deaths [4, 6]. This basic problem is computationally challenging on its own, but it becomes progressively more complex as we consider some of the following real-world constraints [2, 3]:
- Production Restrictions: Vaccines are available in limited quantities for a set amount of time. We must thus consider two time-varying processes (epidemic and vaccine production) when prioritizing vaccines.
- Prioritization: This problem invites an ethical element. Should vaccine distribution aim to slow disease progression or reduce mortality? The latter usually suggests age- and health-based allocation, while the former implies allocation that targets potential super-spreaders.
- Immune Profile: This topic raises several pertinent questions: Who should get the vaccine? What dosage is needed (one or two dose regimens)? Are booster shots necessary? If so, when? And who should receive boosters?
- Hesitancy: Some individuals are hesitant about vaccination for various reasons.
Additional complications include lack of timely data, incomplete understanding of disease and immunological processes, social interventions, genomic variations, and vaccine sharing within a country and between countries. The creation of models that assess various vaccine allocation strategies hence becomes a complex system problem that should address five distinct challenges: (i) Most natural problems are computationally hard; (ii) data is sparse, noisy, lagged, and incomplete; (iii) decisions must be made in near-real time, often with conflicting and evolving objectives; (iv) interventions must be implementable in the real world; and (v) decisions and epidemics coevolve, therefore motivating the need for a robust optimization framework.
Our overall modeling approach addresses these challenges with five steps:
- Step 1: Build a digital twin of the social contact network that is statistically similar to the real-world network but preserves individuals’ privacy and confidentiality.
- Step 2: Initialize the digital twin with ground data.
- Step 3: Use simulations that are oriented in high-performance computing to calibrate and execute a statistical experimental design that studies the specific decision-theoretic question.
- Step 4: Create aggregate statistics from the simulation outputs to compare with measured data.
- Step 5: Analyze the simulated data—often in combination with the extended digital twin—to obtain policy insights [2, 3, 5].
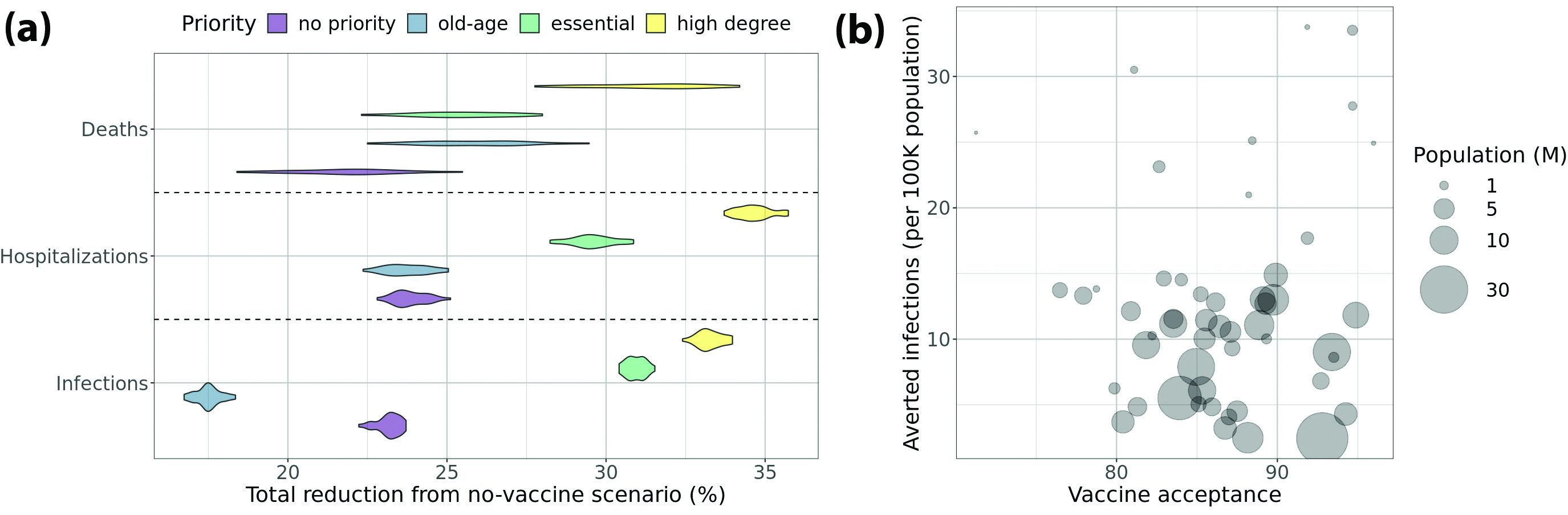
Evaluating Vaccine Prioritization Based on Age and Social Networks
We consider the advantages of vaccine allocation based on individuals’ degrees (number of social contacts) and weighted degrees (total social proximity time) [3]. When COVID-19 vaccines first became available in the U.S. in early 2021, there was a limited supply. A key question was thus as follows: How can we optimally prioritize vaccine allocation to best reduce infections, hospitalizations, and deaths?
To study this query, we utilize a computational experiment on a digital twin of Virginia. We initialize the simulations with (i) an age-stratified COVID-19 disease model; (ii) nodes that represent either susceptible individuals, prior infections, or current infections based on county-level data of daily confirmed cases stratified by age group; and (iii) individual-level compliance with nonpharmaceutical interventions (NPIs) like mask wearing, social distancing, virtual learning for students, and voluntary home isolation of symptomatic cases.
We simulate different vaccine prioritization strategies and compare them with the baseline scenario wherein vaccines are not available. We find that targeting high-degree individuals yields significantly more reductions in infection, hospitalization, and death than allocations with no prioritization or those that prioritize older people or essential workers. Degree-based vaccine allocation is also effective with low vaccine efficacy or relaxed social distancing measures; it is even successful when we cannot accurately estimate node degrees. In fact, this type of allocation works better than the other strategies even when we can only identify 60 percent of the nodes in the first quartile in terms of degree.
The effectiveness of degree-based prioritization stems from the structural changes that occur in the contact network due to vaccination. Consider the snapshot networks at different time points where the edges that are incident on vaccinated or recovered nodes are removed because the disease cannot transmit on them. Unlike other strategies, degree-based vaccination leads to a sparser snapshot network with lower node degrees and a smaller spectral radius (first eigenvalue). Vaccinating high-degree nodes protects those individuals and confers a higher level of indirect protection on the many neighbors with whom they interact. In the context of other prioritization schemes, one can still sub-select individuals with a large amount of social contacts to prioritize vaccine distribution in case of limited supply. See Figure 1a for details.
Evaluating Vaccine Allocation Strategies in Light of Hesitancy
Now we employ artificial intelligence (AI)-driven agent-based models to consider the role of vaccine hesitancy in controlling COVID-19’s spread in the U.S. [2]. In mid-2021, vaccination in the U.S. shifted from a supply-side problem to a demand-side problem due to vaccine hesitancy. We study this issue with a simulation experiment on a digital twin of the U.S., including all 50 states and Washington, D.C. First, we initialize the simulations with the same approach as before based on county-level, age-stratified cases and with basic NPIs in place. We also assign a vaccination schedule—i.e., the number of people receiving each vaccine (Johnson & Johnson, Pfizer, or Moderna) on a weekly basis—to every state based on state vaccine hesitancy levels. The hesitancy level determines the final cumulative fraction of the population that is fully vaccinated. We examine two different trajectories of weekly vaccinations towards the same final coverage: (i) accelerated and (ii) accelerated then decelerated. We also investigate the impact of increasing vaccine acceptance by 10 percent in each state.
Again, we compute the reductions in infection, hospitalization, and death due to vaccination when contrasted with the baseline scenario wherein vaccines are not available. We then compare these scenarios in different settings and find that the number of averted infections/deaths—normalized by population size—is not always greater in states with higher vaccine acceptance. In fact, a significant negative correlation exists between averted infections/deaths and population size. We also discover that the accelerated-decelerated vaccination schedule leads to a smaller reduction of infections/deaths when compared to the accelerated vaccination schedule. This result highlights the health and human costs of vaccine hesitancy and demand saturation. Finally, we realize that increasing the vaccine acceptance rate by 10 percent in each state yields significantly larger reductions in infections/deaths, even with the accelerated-decelerated vaccination schedule. See Figure 1b for a visual depiction.
High-performance Computing, AI, and Network Science
National agent-based models naturally employ AI techniques to support epidemic science. Another application of AI occurs within the synthesis of a contextualized digital twin of the underlying social contact network. The networked agent-based models utilize multi-theory behavioral and disease progression models, and the social contact network’s digital twin is the result of a complex data-driven machine learning process [3]. The use of data-driven techniques—which gather, process, and integrate relevant data from websites—is important in an operationally relevant real-time scenario. More information about how our models are combined in an ensemble is available online at the COVID-19 Scenario Modeling Hub.
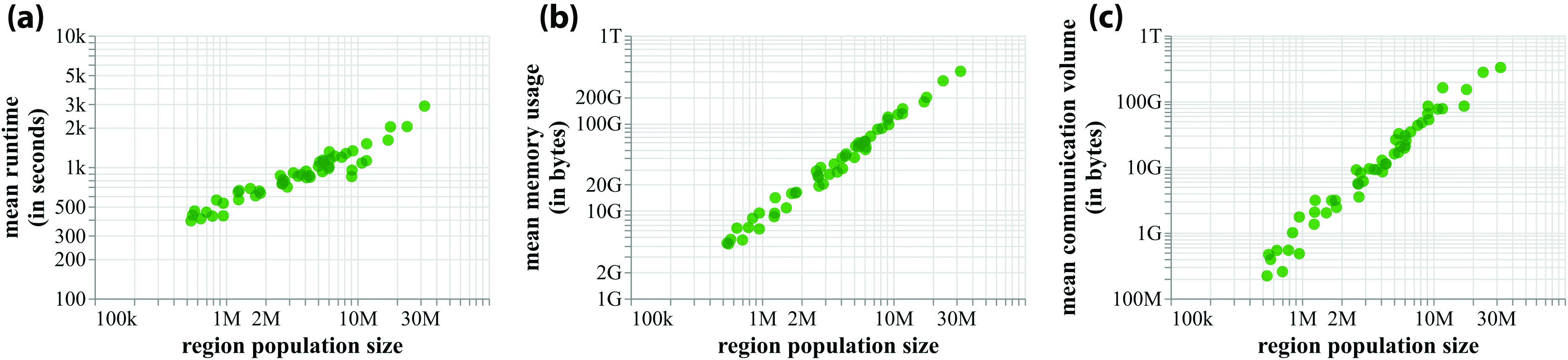
High-performance computing plays a crucial role in our work. Figure 2 displays mean runtimes and memory usage for simulations in one of the studies of all 50 states, thus demonstrating that the requirements scale linearly for the range of pertinent population sizes [1, 2, 5]. Many of our workflows are executed simultaneously on two supercomputers due to the cycles provided by the University of Virginia’s Research Computing Center (Rivanna) and the Pittsburgh Supercomputing Center (Bridges) as a part of the National Science Foundation’s Extreme Science and Engineering Discovery Environment (XSEDE) project. Figure 3 illustrates the overall data flow between the two supercomputers and the specific steps that occur on each machine [5].
![<strong>Figure 3.</strong> Workflow with the collection and exchange of data at various stages of computation [2, 5]. Figure courtesy of Jiangzhuo Chen and Madhav Marathe.](/media/tttf3ttu/figure3.jpg)
Our specific workflow uses approximately 20,000 cores on Bridges and 3,000 cores on Rivanna. When we first employed the pipeline, we were granted access to 30,000 cores on Bridges each night. However, this level of generous access was of course not sustainable and we now reserve about 7,000 cores on Bridges. As a result of this change, we relied on packing methods to pack jobs efficiently on the cluster from fall 2020 [5]. Our current approach is an online scheduling method that utilizes both machines as cycles become available [1]. This new allocation scheme better shares the machines with other users and carries out more reliable computations.
In this article, we describe a data-driven AI approach that leverages advances in network science and high-performance computing to support ongoing COVID-19 pandemic response efforts in real time. Real-time epidemic science is a nascent field, and we aim to outline early steps toward the realization of relevant goals.
Acknowledgments: The authors thank members of the Biocomplexity Institute’s COVID-19 Pandemic Response Team at the University of Virginia (UVA); UVA’s Network Systems Science and Advanced Computing Division; UVA’s Research Computing Center; Shawn Brown and Tom Maiden of the Pittsburgh Supercomputing Center; John Towns of the Extreme Science and Engineering Discovery Environment; and our partners at the Centers for Disease Control and Prevention, Virginia Department of Health, National Science Foundation, and COVID-19 Scenario Modeling Hub. This work was partially supported by the NIH Grant R01GM109718, VDH Grant PV-BII, VDH COVID-19 Modeling Program, VDH-21-501-0135, NSF Grant OAC-1916805, NSF CCF-1918656, CCF-1917819, NSF RAPID CNS-2028004, NSF RAPID OAC-2027541, DTRA subcontract/ARA S-D00189-15-TO-01-UVA, and NSF XSEDE TG-BIO210084.
References
[1] Bhattacharya, P., Chen, J., Hoops, S., Machi, D., & Marathe, M. (2021). Data-driven scalable pipeline using national agent-based models for real-time pandemic response and decision support. Paper presented at the International conference for high performance computing, networking, storage, and analysis, St. Louis, MO.
[2] Bhattacharya, P., Machi, D., Chen, J., Hoops, S., Lewis, B., Mortveit, H., ... Marathe, M. (2021). AI-driven agent-based models to study the role of vaccine acceptance in controlling COVID-19 spread in the US. In 2021 IEEE international conference on big data. Institute of Electrical and Electronics Engineers.
[3] Chen, J., Hoops, S., Marathe, A., Mortveit, H., Lewis, B., Venkatramanan, S., … Marathe, M. (2021). Prioritizing allocation of COVID-19 vaccines based on social contacts increases vaccination effectiveness. Preprint, medRxiv.
[4] Eubank, S., Guclu, H., Kumar, V.S.A., Marathe, M.V., Srinivasan, A., Toroczkai, Z., & Wang, N. (2004). Modeling disease outbreaks in realistic urban social networks. Nature, 429(6988), 180-184.
[5] Machi, D., Bhattacharya, P., Hoops, S., Chen, J., Mortveit, H., Venkatramanan, S., … Marathe, M.V. (2021). Scalable epidemiological workflows to support COVID-19 planning and response. In Proc. 35th IEEE international parallel and distributed processing symposium. Institute of Electrical and Electronics Engineers.
[6] Marathe, M., & Vullikanti, A.K.S. (2013). Computational epidemiology. Commun. ACM, 56(7), 88-96.
About the Authors
Jiangzhuo Chen
Research Associate Professor, University of Virginia
Jiangzhuo Chen is a research associate professor in the Network Systems Science and Advanced Computing Division of the University of Virginia’s Biocomplexity Institute.
Stefan Hoops
Research Associate Professor, University of Virginia
Stefan Hoops is a research associate professor in the Network Systems Science and Advanced Computing Division of the University of Virginia’s Biocomplexity Institute.
Parantapa Bhattacharya
Research Scientist, Biocomplexity Institute
Parantapa Bhattacharya is a research scientist in the Network Systems Science and Advanced Computing Division of the Biocomplexity Institute.
Dustin Machi
Senior Software Architect, Biocomplexity Institute
Dustin Machi is a senior software architect in the Network Systems Science and Advanced Computing Division of the Biocomplexity Institute.
Madhav Marathe
Distinguished professor, Biocomplexity Institute
Madhav Marathe is an endowed Distinguished Professor in Biocomplexity, director of the Network Systems Science and Advanced Computing Division in the Biocomplexity Institute, and a tenured professor of computer science at the University of Virginia. His areas of expertise are network science, artificial intelligence, high-performance computing, computational epidemiology, biological and socially coupled systems, and data analytics.
Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
