
Robust Poster Sessions at MDS24 Highlight Diverse Applications of Data Science
The 2024 SIAM Conference on Mathematics of Data Science (MDS24), which took place last October in Atlanta, Ga., featured a vibrant five-day sequence of evening poster sessions. To promote these sessions and encourage lively discussions about the meeting’s various themes, the MDS24 co-chairs required all minisymposium organizers to submit a series of posters that matched the number of talks in each minisymposium [1]. This stipulation—a first for the SIAM community—resulted in a rich spread of posters, attracted large crowds at the daily sessions, and encouraged broader engagement between attendees at different career stages and across employment sectors.
To provide a robust sense of the variety of featured research topics, we highlight a stratified random sample of the roughly 550 posters on display at MDS24.
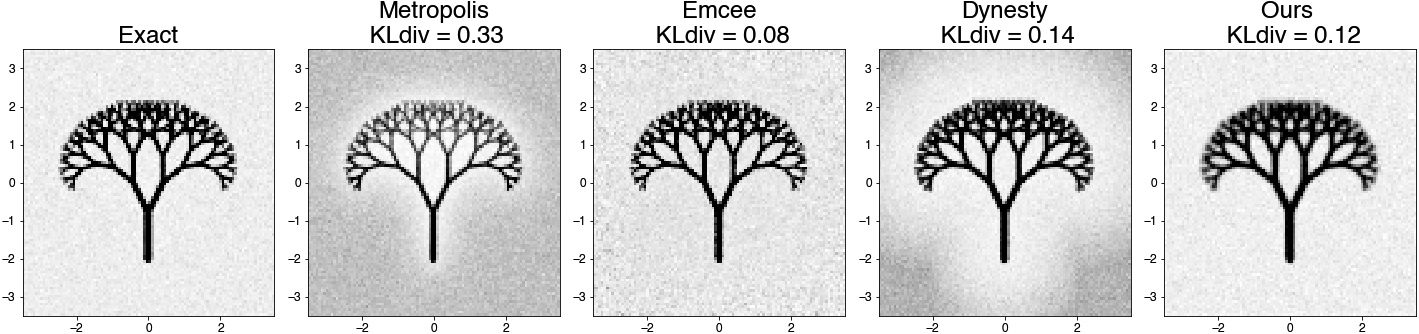
Supervised Learning Framework for Efficient Sampling of High-dimensional, Multimodal Distributions
Hoang Tran, a staff mathematician at Oak Ridge National Laboratory, presented work on the synthetic generation and sampling of high-dimensional, multimodal probability distributions. This mathematical setting describes most generative models for text and images, among other applications; Tran’s research focuses specifically on supervised methods for the sampling of multimodal distributions.
Common frameworks such as Markov chain Monte Carlo or generative adversarial networks suffer from issues like slow convergence, vanishing gradients, poor mixing, and mode trapping. Tran’s framework alleviates these complications by using a divide-and-conquer approach within the subdomains of a multimodal distribution. His technique relies on several modular steps. First, it solves an optimization problem on the target distribution to identify potential modes, then trains a classifier whose decision boundaries partition the domains that correspond with each mode. A diffusion model generates labeled data for the unimodal distribution in every subdomain, and a neural network learns the same sampler in a supervised manner. One can then join and rescale these samplers to correct the ratios between modes.
Tran illustrated this procedure with a proof-of-concept implementation that he tested on both images and synthetic data (see Figure 1). Given the generality of the modular steps in this process, he and his colleagues hope to gradually refine the framework piece by piece.
Analysis of Reporting Trends in Russo-Ukrainian Conflicts Through Topic Modeling Algorithms
Nya Feinstein, a recent graduate of West Virginia University, presented an analysis of 15,537 news articles from the Ukrainian News Agency that she mined from LexisNexis, with a query on articles from 2011 to 2023 that contain information about Russia. She utilized latent Dirichlet allocation (LDA) and BERTopic—two natural language processing tools—to evaluate the contents of these articles and quantify the relative frequency of the appearance of certain topics over time, such as energy (e.g., “gas” or “nuclear”) and strategy (e.g., “defense” or “security”). This database also allowed her to identify relative jumps or declines in different topics before and after major events—like Russia’s 2014 annexation of Crimea and the 2022 Russian invasion—from a Ukrainian lens. While Feinstein observed many similarities between the content that LDA and BERTopic extracted, she also encountered some differences and challenges — especially with the use of BERTopic. She aims to refine these tools as a method of conflict forecasting and trend analysis based on news data.
Wasserstein Convergence Guarantees for a General Class of Score-based Generative Models
Hoang Nguyen, a graduate student at Florida State University who will soon join Meta as a research scientist, prefaced his work by formulating generative diffusion models in the context of stochastic differential equations (SDEs). A common forward process in SDEs is \(d\mathbf{x}_t = -f(t)\mathbf{x}_t dt + g(t) dW_t\), where \(\mathbf{x}_0 \sim p_0\); here, \(p_0\) is a desired but unknown data distribution, and \(f(t)\) and \(g(t)\) are respectively drift and diffusion terms. A reverse process for \(\tilde{\mathbf{x}}_t\) runs this procedure backward in time and—under certain assumptions—obeys a more sophisticated SDE that depends on \(f\), \(g\), and the probability density of \(\mathbf{x}_t\). The formalization of this reverse process enables the recovery of \(p_0\) for various choices of \(f\), \(g\), and other parameters.
Nguyen and his collaborators proved an overall bound on the 2-Wasserstein distance of a simulated density of the reverse process—that is, \(\mathcal{L}(\mathbf{y}_K)\)—to the target distribution \(p_0\), specifically \(\mathcal{W}(\mathcal{L}(\mathbf{y}_K), p_0)\). They used this knowledge to identify bounds on combinations of algebraic and/or exponential forms for \(f(t)\) and \(g(t)\), and ultimately prescribed an optimal step size based on the drift and diffusion terms. The group implemented this scheduler for image generation with the well-known CIFAR-10 dataset, which led to practical performance improvements. In the future, Nguyen hopes to relax some of the theoretical assumptions and apply the framework to large-scale generative diffusion models.
Classifying Imbalanced Data
Karen Medlin, a graduate student at the University of North Carolina at Chapel Hill, studies methods that handle imbalanced datasets in machine learning (ML) classification tasks. Datasets in which the number of data points of the “majority” class (e.g., class \(0\)) greatly outnumber those of the “minority” class (e.g., class \(1\)) pose a fundamental challenge for scientists. Because out-of-the-box techniques to train a robust classifier often fail with imbalanced data, Medlin’s approach instead considers majority undersampling with bilevel optimization as a framework for any ML model. Here, the formation of an energy functional \(J(S_M, w^*)\) is based on the undersampling of majority class \(S_M\) and model parameters \(w^*\), where the constraint is dependent on solving the parameters on this subset of data. In practice, this type of optimization uses an alternating scheme wherein a proposed undersampling trains a classifier that then passes the new set of learned parameters to the functional \(J\). Class imbalance is common in anomaly detection and rare event forecasting, so Medlin hopes that researchers will eventually apply this methodology to such data.
Embrace Rejection: Kernel Matrix Approximation by Accelerated Randomly Pivoted Cholesky
Ethan Epperly, a graduate student at the California Institute of Technology, focuses his research on computational linear algebra at the interface of scientific ML. Many kernel methods in ML require the evaluation of a function \(\kappa(\mathbf{x}, \mathbf{x}')\) at all pairs of a dataset’s elements. The formation of this positive semidefinite kernel matrix, which necessitates \(O(N^2)\) kernel evaluations with \(N\) datapoints, can act as a bottleneck due to limitations in space or compute time. To alleviate this barrier, one can replace data matrix \(A\) with a rank-\(k\) approximation \(\widehat{A} = F F^T\) that accelerates downstream algorithms. For any symmetric positive semidefinite matrix \(A\), the standard randomly pivoted Cholesky (RPCholesky) algorithm produces this type of \(F\) based on outer product updates \(\widehat{A} \gets \widehat{A} + A_s \, A_s^T/A_{s,s}\), followed by a deflation step on \(A\). The pivot \(s=s_i\) is randomly selected and weighted by the diagonal entries of the current \(A\). This process is sequential, as the deflation at step \(i\) affects the distribution for sampling \(s_{i+1}\).

To accelerate the algorithm, Epperly and his colleagues developed a block version of RPCholesky that samples sets of indices with rejection sampling and uses a block-based update for \(\widehat{A}\). Their method begins with a proposed set of pivots at iteration \(i\), \(S_i\); after submatrix \(A_{S_i,S_i}\) is scanned, each proposed pivot \(s’\) is rejected with probability \(A_{s’}^T A_{S_i, S_i} ^\dagger A_{s’}/A_{s’,s’}\). Once a final set of pivots \(S_i\) is selected, one must then perform a block update of \(\widehat{A}\) and a deflation of \(A\) (possibly greater than rank \(1\)). Experiments revealed a five to \(40\times\) speedup over traditional RPCholesky. In practice, this method achieves state-of-the-art speed in fitting potential energy functionals when compared to alternatives like uniform sampling, greedy sampling, and ridge leverage score sampling.
A Training-free Conditional Diffusion Model for Learning Stochastic Dynamical Systems
Yanfang Liu, an assistant professor at Middle Tennessee State University, presented her work on the supervised learning of unknown SDEs through what she calls a conditional diffusion model for flow map learning. Conditional diffusion models consist of the forward SDE \(dZ_\tau = h(\tau) Z_\tau d\tau + g(\tau) dW_\tau\) and the associated reverse-time equation. Liu and her collaborators determined that it is possible to approximate the score function \(S(Z_\tau, \tau) = \nabla_z \log p(Z_\tau)\) via a Monte-Carlo-based estimation that requires a prior dataset of the SDE’s input/output pairs. Given this newfound knowledge, Liu proposed an algorithm that iteratively refines the estimated score function \(S(Z_\tau, \tau)\) and utilizes it to produce a new data sample. With an expanded training dataset, one can then use a neural network to approximate the generative model. Liu ultimately observed a performance level that matched or exceeded generative adversarial networks on a collection of classical SDE models, as measured by end-time mean and standard deviation.
Conclusions and Broader Trends
These and the numerous other poster topics at MDS24 reflected emerging trends in the mathematical data science space. The presentations spotlighted here include application projects, classical applied frameworks as lenses for algorithm development and computational study, and analytical inroads that reflect the state of the art in data science. No one theme overwhelmingly dominated the poster sessions; out of the approximately 550 displays, 30 addressed generative modeling; 44 focused on topological, geometrical, and/or distributional/Wasserstein-based perspectives; 66 examined neural-related subjects; and 10 or so detailed other research areas.
The applied mathematics community undoubtedly spans a diverse set of interests and entry points within the broader data science community, and we look forward to witnessing the continued evolution of these connections next year at MDS26.
References
[1] Chi, E.C., Gleich, D.F., & Ward, R. (2025, January 21). Artificial intelligence tools facilitate MDS24 conference scheduling. SIAM News, 58(1), p. 8.
About the Author
Manuchehr Aminian
Associate professor, California State Polytechnic University
Manuchehr Aminian is an associate professor in the Department of Mathematics and Statistics at California State Polytechnic University, Pomona. His research interests include mathematical modeling, partial differential equations, and mathematical methods in data science.


Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
