
Science-driven Machine Learning for Environmental Challenges
Traditional scientific models of environmental systems must make numerous basic assumptions that affect the realism of the model’s representations. These frameworks require significant amounts of domain knowledge and potentially time-consuming experiments, and may be high-dimensional and thus computationally expensive.
Machine learning models present an alternative to traditional modeling schemes that can avoid several of these pitfalls. However, they have their own requirements that can often pose issues in environmental contexts. “For many environmental science problems, the more you build out the model, the hungrier it gets for data,” Esha Saha of the University of Alberta said. Geoscience researchers may encounter numerous limitations on data: reports from government bodies or companies can be difficult to obtain and are subject to human errors; data from weather stations are subject to calibration errors and often limited in temporal scope; and for satellite imaging, the area of interest may be frequently obscured by clouds or not receive frequent measurements.
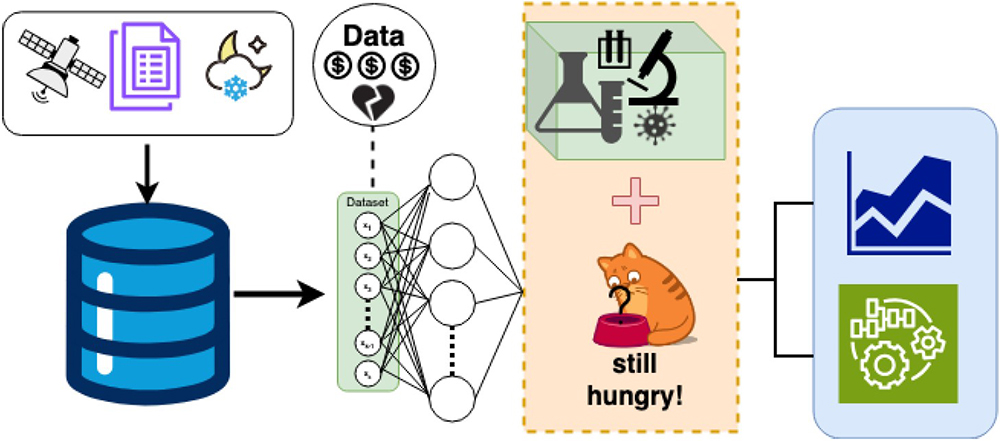
In a contributed presentation at the Third Joint SIAM/CAIMS Annual Meetings—which are currently taking place in Montréal, Québec, Canada—Saha discussed the challenges that data sparsity poses for machine learning models in environmental science, and explained the benefits of incorporating scientific knowledge into machine learning models to improve outcomes for areas without high data coverage (see Figure 1). “For places with sparse data, we can try to fill in the gaps with physics, chemistry, or whatever we know,” Saha said. Potential techniques include constrained optimization, physics-informed neural networks, and the sparse identification of nonlinear dynamics.
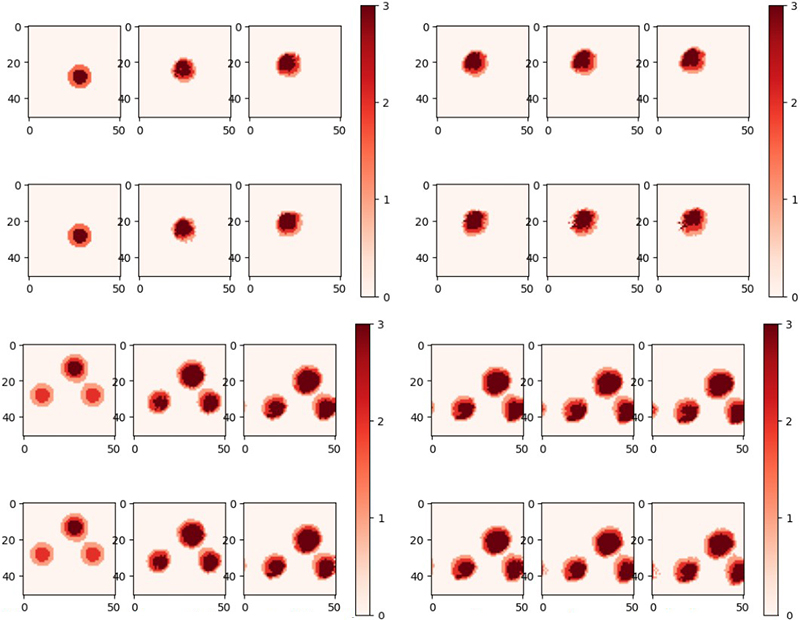
Saha first provided an example of modeling wildfires — a pressing application, as climate change is driving an increase in this natural disaster’s incidence and intensity. In the case that fire is reported in multiple locations within a region, is it possible to use a machine learning approach to fill in any gaps in the map and predict how the situation might evolve in the future? The Canadian Wildland Fire Information System, which does not incorporate any machine learning aspects, serves as a useful benchmark for this effort.
Saha proposed a learnable diffusion-advection approach that uses both data and physical principles to drive physics-informed machine learning for wildfires. “For now, we only have research with respect to simulated data,” she said. Figure 2 depicts the training and validation of this model in the case of single and multiple fires with simulated data.
Another environmental challenge in which machine learning can play a role relates to oil sands: deposits in which sands and other sediments are soaked in petroleum, necessitating heavy industrial processing to extract the oil. “Canada has one of the world’s largest oil sands deposits,” Saha said. After oil is extracted from these sites, the remains are dumped into artificial tailings ponds, which are major sources of pollutants like methane — a gas that is 28 times more effective than carbon dioxide at trapping heat, but has a shorter lifespan.
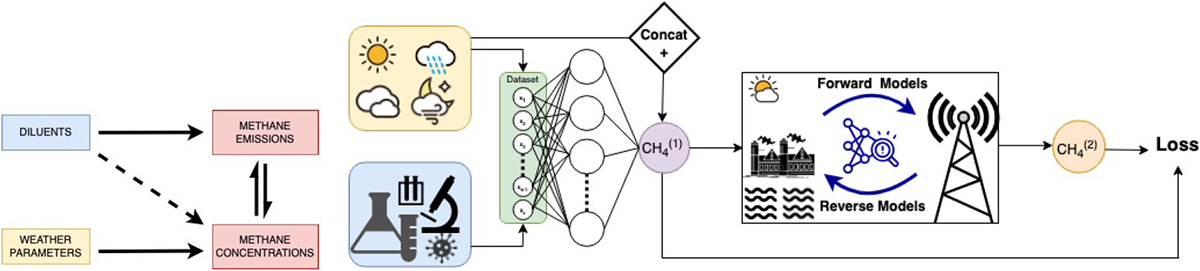
Based on modeling, knowledge of weather patterns, and methane concentration data in the region, Saha aimed to enable the remote tracking of methane emissions from oil sands tailings ponds. “First, I want to give a ground reality of how much data is really out there,” she said, noting that there are only a few sites in Canada where she could find sufficient data on multiple timescales and axes to enable a deep analysis. Figure 3 provides a recipe for the cocktail of models in Saha’s proposed framework for methane tracking.
The resulting predictions of methane emissions in 2020 and 2023 indicated that official reports were underestimating the amount of methane being emitted by these tailings pond sites by a factor of approximately three. “Based on methane concentration results in that region, we found out that these spots are still emitting a lot more methane than thought,” Saha said.
In the future, Saha hopes to augment the oil sands research by investigating other methane sources, incorporating more remote sensing, and adding physical constraints to the model. For the wildfire application, the next steps will be testing with real data and examining additional potential machine learning frameworks. Overall, the use of science-based machine learning can lessen the load on computational resources and offers additional insights into the nonlinear relationships between variables. Ensuring that machine learning models are aware of physical laws permits more robust training and, ultimately, better scientific outcomes.
Acknowledgements: Esha Saha acknowledged collaborators Oscar Wang of the University of Richmond and Amit Chakraborty, Pablo Venegas Garcia, Russell Milne, and Hao Wang of the University of Alberta. She also acknowledged funding from the Grant Notley Postdoctoral Fellowship and Travel Award and NSERC Alliance Missions Project.
References
[1] Saha, E., & Wang, H. (2025). Machine learning enhanced wildfire mapping. Under preparation.
[2] Saha, E., Wang, O., Chakraborty, A.K., Garcia, P.V., Milne, R., & Wang, H. (2024). Methane projections from Canada’s oil sands tailings using scientific deep learning reveal significant underestimation. Preprint, arXiv:2411.06741.
[3] Sysoeva, L., Bouderbala, I., Kent, M., Saha, E., Zambrano-Luna, B., Milne, R., & Wang, H. (2024). Decoding methane concentration in Alberta oil sands: A machine learning exploration. Ecol. Indic., 170, 112835.
About the Author
Jillian Kunze
Master's student, Drexel University
Jillian Kunze is the former associate editor of SIAM News. She is currently a master’s student in data science at Drexel University.

Related Reading

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
