
The Emerging Science of Machine Learning Benchmarks
Machine learning turns on one simple trick: Split the data into training and test sets. Anything goes on the training set. Rank models on the test set and let model builders compete. Call it a benchmark.
Machine learning researchers cherish a good tradition of lamenting the apparent shortcomings of benchmarks. Critics argue that static test sets and metrics promote narrow research objectives, stifling more creative scientific pursuits. Benchmarks also incentivize gaming; in fact, Goodhart's Law cautions against applying competitive pressure to statistical measurement. Over time, researchers may overfit to benchmarks, building models that exploit data artifacts. As a result, test set performance draws a skewed picture of model capabilities that deceives us — especially when comparing humans and machines. To top off the list of issues, there are a slew of reasons why things don't transfer well from benchmarks to the real world.
These scorching critiques go hand in hand with serious ethical objections. Benchmarks reinforce and perpetuate biases in our representation of people, social relationships, culture, and society. Worse, the creation of massive human-annotated datasets extracts labor from a marginalized workforce that is disenfranchised from the economic gains of their efforts.
All of this is true.
Many have said it well. Many have argued it convincingly. I'm particularly drawn to the claim that benchmarks serve industry objectives, giving big tech labs a structural advantage. The case against benchmarks is clear, in my view.
What's far less clear is the scientific case for benchmarks.
It is an undeniable fact that benchmarks have been successful as a driver of progress in the field. ImageNet was inseparable from the deep learning revolution of the 2010s, with companies competing fiercely over the best dog breed classifiers. The difference between a Blenheim Spaniel and a Welsh Springer Spaniel became a matter of serious rivalry. A decade later, language model benchmarks reached geopolitical significance in the global competition over artificial intelligence. Tech executives now recite their company's number on the Massive Multitask Language Understanding (MMLU) dataset—a set of 14,042 college-level multiple choice questions—in presentations to shareholders. Earlier this year, news broke that David beat Goliath on reasoning benchmarks, a sensation that shook global stock markets [3].
Benchmarks come and go, but their centrality hasn't changed. Competitive leaderboard climbing has been the main way machine learning advances.
If we accept that progress in artificial intelligence is real, we must also accept that benchmarks have, in some sense, worked. But this fact is more of a hindsight observation than a scientific lesson. Benchmarks emerged in the early days of pattern recognition. They followed no scientific principles. To the extent that benchmarks had any theoretical support, that theory was readily invalidated by how people used them in practice. Statistics prescribed locking test sets in a vault, but practitioners did the opposite. They put them on the internet for everyone to use freely. Popular benchmarks draw millions of downloads and evaluations as model builders incrementally compete over better numbers.
Benchmarks are the mistake that made machine learning. They shouldn't have worked, and yet they did.
Benchmarks emerged from little more than common sense and intuition. They appeared in the late 1950s, had some life during the 1960s, hibernated throughout the 1970s, and sprung to popularity in the late 1980s when pattern recognition became machine learning. Today, benchmarks are so ubiquitous that we take them for granted. And we expect them to do their job. After all, they have in the past.
The deep learning revolution of the 2010s was a triumph for the benchmarking enterprise. The ImageNet benchmark was at the center of all cutting-edge advances in image classification with deep convolutional neural networks. Despite massive competitive pressure, it reliably supported model improvements for nearly a decade. A sprawling software ecosystem grew around ImageNet, making it ever simpler and faster to develop models on the benchmark.
Even its tiny cousin, CIFAR-10, did surprisingly well. Model builders often put CIFAR-10 into the development loop for architecture search. Once they found a promising candidate architecture, they would then scale it up to ImageNet. Legend has it that some of the best ImageNet architectures first saw the light of day on CIFAR-10. Even though CIFAR-10 contains only tiny pixelated test images from ten classes—such as frogs, trucks, and ships—the dataset was any model builder's Swiss Army knife for many years. The platform Papers With Code hosts more than 15,000 papers with CIFAR-10 evaluations. This does not count the numerous evaluations that went into every single one of these papers, or the enormous amount of engineering work that used the dataset in one way or another.

That so much work should hinge on so little data might seem reckless.
But with the benefit of hindsight, researchers verified that the ranking of popular models on CIFAR-10 largely agrees with the ranking of the same models on ImageNet. In turn, model rankings on ImageNet transfer well to many other datasets; the better a model performs on ImageNet, the better it performs elsewhere too. Researchers even created a dataset called ImageNot that is full of noisy web crawl data, designed to stray as far as possible from ImageNet while matching only its size [5]. When we train all key ImageNet-era architectures on ImageNot from scratch, the model rankings turn out to be the same (see Figure 1).
Model rankings replicate to a surprising degree, which is in stark contrast with absolute performance numbers. Model accuracies and other metrics don't replicate from one dataset to the other, even when the datasets are similar. This means that model rankings—rather than model evaluations—are the primary scientific export of machine learning benchmarks.
The ImageNet era ended not with computer vision but with natural language processing, as the new transformer architecture triumphed over the sluggish recurrent neural networks that had long been the workhorse for sequence problems of all kinds. Transformers are much easier to scale up and quickly took over. The simple training objective of next token prediction in a text sequence freed training data from human annotation. Companies quickly scraped up anything they could find on the internet, from chat messages and Reddit rants to humanity's finest writing. New scaling laws suggested that training loss decreases predictably as you jointly increase dataset size, number of model parameters, and training compute. For a while, it seemed like the only thing left to do was sit back and watch new abilities emerge in explosively growing models. But where did this new reality leave benchmarks?
The current era departed from the old in some significant ways.
First, models now train on the internet — or at least on massive, minimally curated web crawls. At the point of evaluation, we therefore don't know and can't control the training data that the model saw. This turns out to have profound implications for benchmarking. The extent to which a model has encountered training data that is similar to the test task skews model comparisons and threatens the validity of model rankings. A worse model may have simply crammed better for the test. Would you prefer a worse student who was better prepared for the exam, or a better student who was less prepared? If you prefer the latter, then you'll need to adjust for the difference in test preparation. Thankfully, this can be done by fine-tuning each model on the same task-specific data before evaluation, without the need to train from scratch [1].
Second, models no longer solve a single task, but can instead be prompted to tackle pretty much any task. In response, multitask benchmarks have emerged as the de facto standard to provide a holistic evaluation of recent models by aggregating performance across numerous tasks into a single ranking. The aggregation of rankings, however, is a thorny problem in social choice theory that has no perfect solution. If we work from an analogy between multitask benchmarks and voting systems, ideas from social choice theory reveal inherent tradeoffs that multitask benchmarks face. Specifically, a greater diversity of tasks comes at the cost of greater sensitivity to irrelevant changes [6]. For example, adding weak models to popular multitask benchmarks can change the order of top contenders. The familiar stability of model rankings, characteristic of the ImageNet era, therefore does not extend to multitask benchmarks in the large language model (LLM) era (see Figure 2a).
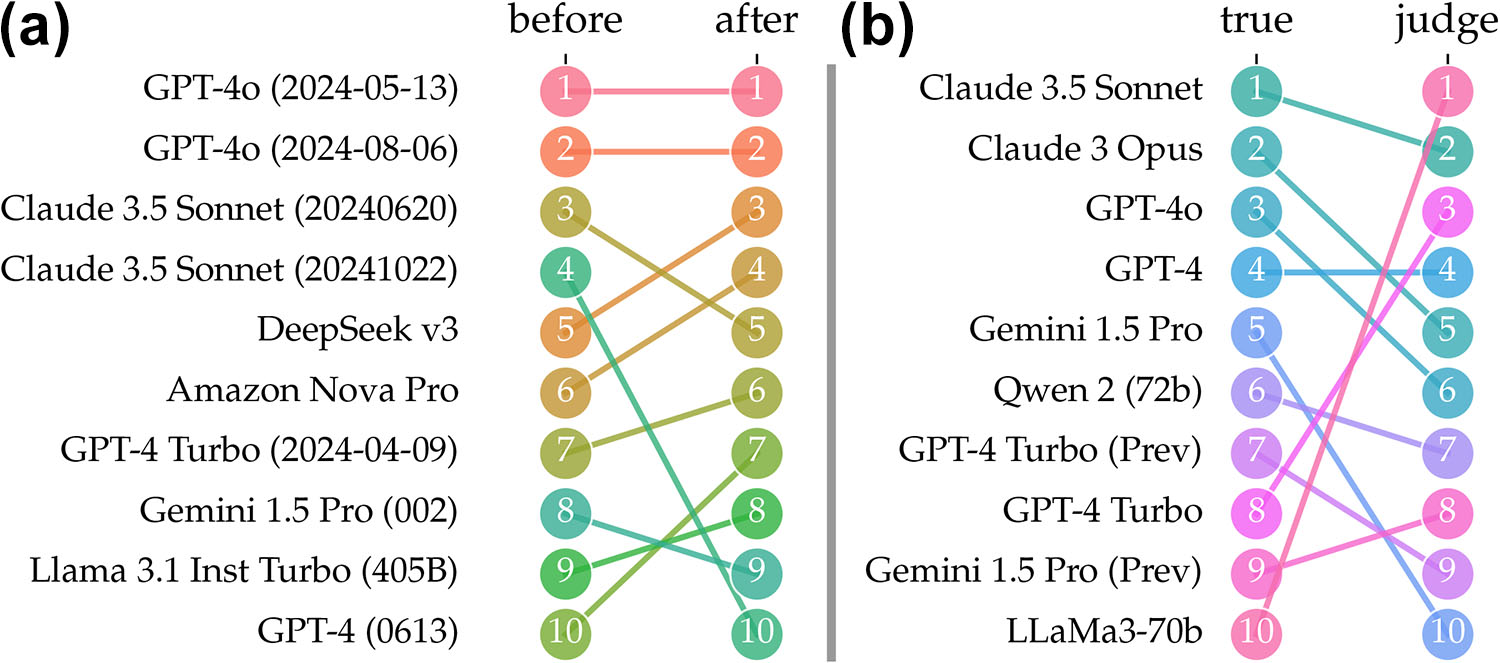
The final problem that benchmarking faces is an existential one. As model capabilities exceed those of human evaluators, researchers are running out of ways to test new models. There's hope that models might be able to evaluate each other, but the idea of using models as judges runs into some serious hurdles. Unsurprisingly, LLM judges are biased in their own favor (see Figure 2b) [2]. Intriguing recent debiasing methods from statistics promise to debias model predictions from a few human ground truth labels. Unfortunately, at the evaluation frontier—where new models are at least as good as the judge—even the optimal debiasing method is no better than collecting twice as many ground truth labels for evaluation.
So, will our old engine of progress grind to a halt?
In moments of crisis, we tend to accelerate. What if we instead step back and ask why we expected benchmarks to work in the first place — and for what purpose? This question leads us into uncharted territory. For the longest time, we took benchmarks for granted and didn’t bother to work out the underlying methodology. We got away with it mostly by sheer luck, but we might not be as lucky this time.
Over the last decade, however, a growing body of work has begun to map the foundations for a science of machine learning benchmarks. What emerges is a rich set of observations—both theoretical and empirical—raising intriguing open problems that deserve the community’s attention. If benchmarks are to serve us well in the future, we must put them on solid scientific ground. My upcoming book, The Emerging Science of Machine Learning Benchmarks, supports this development [4].
Moritz Hardt delivered an invited presentation on this research at the 2024 SIAM Conference on Mathematics of Data Science, which took place in Atlanta, Ga., last October.
References
[1] Dominguez-Olmedo, R., Dorner, F.E., & Hardt, M. (2025). Training on the test task confounds evaluation and emergence. In The thirteenth international conference on learning representations (ICLR 2025). Singapore.
[2] Dorner, F.E., Nastl, V.Y., & Hardt, M. (2025). Limits to scalable evaluation at the frontier: LLM as judge won't beat twice the data. In The thirteenth international conference on learning representations (ICLR 2025). Singapore.
[3] Goldman, D., & Egan, M. (2025, January 27). A shocking Chinese AI advancement called DeepSeek is sending US stocks plunging. CNN. Retrieved from https://edition.cnn.com/2025/01/27/tech/deepseek-stocks-ai-china.
[4] Hardt, M. (2025). The emerging science of machine learning benchmarks. To be published. Available online at https://mlbenchmarks.org.
[5] Salaudeen, O., & Hardt, M. (2024). ImageNot: A contrast with ImageNet preserves model rankings. Preprint, arXiv:2404.02112.
[6] Zhang, G., & Hardt, M. (2024). Inherent trade-offs between diversity and stability in multi-task benchmarks. In The 41st international conference on machine learning (ICML 2024). Vienna, Austria.
About the Author
Moritz Hardt
Director, Max Planck Institute for Intelligent Systems
Moritz Hardt is a director at the Max Planck Institute for Intelligent Systems, where his group strengthens the scientific foundations of machine learning. He co-authored Fairness and Machine Learning: Limitations and Opportunities (published by MIT Press) and Patterns, Predictions, and Actions: Foundations of Machine Learning (published by Princeton University Press).

Related Reading

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
