
The Ethics of Artificial Intelligence-Generated Art
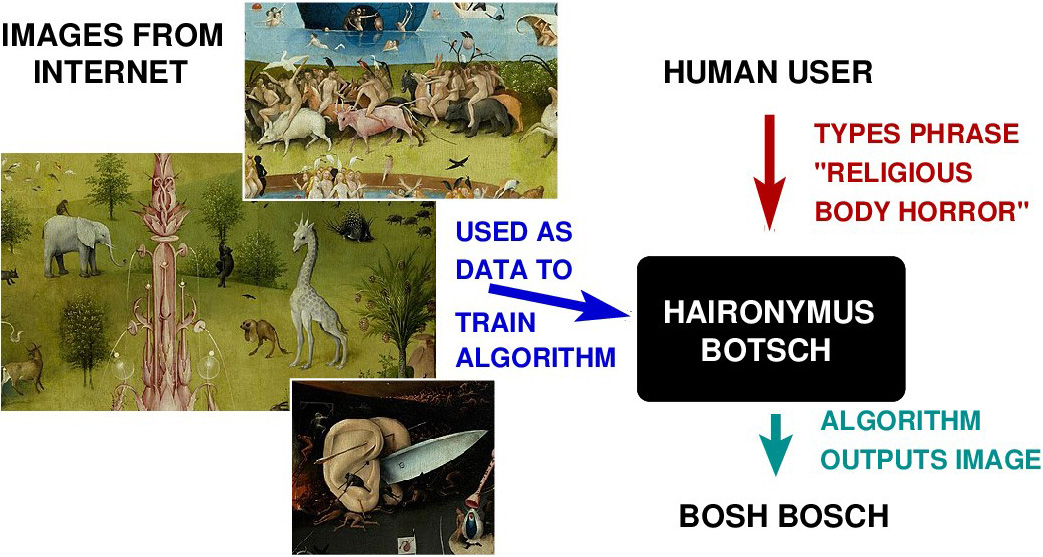
In recent months, many people have begun to explore a new pastime: generating their own images using several widely-distributed programs such as DALL-E, Midjourney, and Stable Diffusion. These programs offer a straightforward interface wherein nontechnical users can input a descriptive phrase and receive corresponding pictures, or at least amusingly bad approximations of the results they intended. For most users, such artificial intelligence1 (AI)-generated art is harmless fun that requires no computer graphics skills to produce and is suitable for social media posts (see Figure 1).
However, AI algorithms combine aspects of existing data to generate their outputs. DALL-E, Stable Diffusion, and other popular programs pull images directly from the internet to train their algorithms. Though these images might be easily obtainable—from the huge Google Images database, for example—the creators have not always licensed their art for reuse or use in the production of derivative works. In other words, while publications like SIAM News obtain permission before disseminating restricted-license images, popular AI algorithms do not distinguish between pictures that are freely usable and those that are not.
For this and other reasons, the problems associated with AI art generally fall into three basic categories: (i) Ethical questions of data sourcing, (ii) legal questions involving copyright and licensing, and (iii) technical questions that surround the algorithms and their frequent reinforcement of biases. “This is a new realm for an extant conversation that’s happening with algorithmic training data in other realms,” Damien Williams, a professor of philosophy and data science at the University of North Carolina at Charlotte, said. “Do the people training these systems have anything like meaningfully informed consent? These are questions in other areas of algorithmic ethics, but they’re being brought over into a very visible conversation about visual art and illustration. And I think that’s a good thing.”
To complicate matters, the ethics of AI-generated art may not translate directly into legal arguments. “From a machine learning perspective, you want the biggest possible dataset, copyright be damned,” Meredith Rose, a senior policy counsel at Public Knowledge, said. Public Knowledge is a 501(c)(3) organization that, according to its mission statement, “promotes freedom of expression, an open internet, and access to affordable communications tools and creative works.”
At the same time, Rose noted that the sheer amount of training data for DALL-E and its ilk makes it nearly impossible to prove that a particular copyright-protected piece of art was part of a specific dataset that was utilized to generate the AI art item in question. Unless a user specifically asks for output in the style of a specific artist—as happened recently when beloved comics artist Kim Jung Gi died and multiple people used his art as training data for algorithmic homages, to the horror of his friends and colleagues—individual creators would have trouble arguing misuse of their art in a court of law.
“From a strictly copyright perspective, I don’t know that there’s a clear answer to this,” Rose said. “To the extent that any answer looks more probable, my opinion is that the fair-use case is pretty strong.” In other words, the same laws that allow for parodies and (at least some) hip-hop samples might apply, but the courts generally have not yet caught up with the specific details of AI art.
The Training Wheels Come Off
While individuals have been making art with computers for more than 50 years, AI-based art is just now coming into its own. Nevertheless, many of its associated ethical and legal issues are not new. From Dadaist “readymades” to hip-hop sampling and parody news magazines, nearly every creative discipline has explored the limits of incorporating other people’s material into new art. In fact, visual artists often learn by imitating the “masters” of the field — sometimes even directly copying their works.
These historical points relate to the technical side of AI art, which in many respects is the simplest of the three aforementioned issues. Some algorithms already restrict content for both input and output; for instance, DALL-E forbids sexual and broadly-defined “obscene” content. Through her own experimentation efforts, Rose has also found that DALL-E does not produce images of certain licensed properties, like those owned by the notoriously litigious Walt Disney Corporation.
Williams argued that these existing limitations show that developers can write algorithms to only use data that belongs to creators who have explicitly granted reuse and remixing permissions. “We have a wide array of available imagery and information that we can make use of without impinging on the rights of someone else,” he said, stressing that ethical considerations are involved in the use of a creator’s material even when that material is licensed for open distribution. “There are a lot of people who believe in some version of open-source information but don’t necessarily want their imagery or their data being used to train a Google system. Ideologically, those things are not necessarily at odds.”
Beyond licensing issues, training data for AI art can end up selecting subsets of available data in biased ways. DALL-E’s restriction on sexual content means that its pool of images excludes many innocuous pictures of women due to a strict interpretation of the definition of “sexual.” As a result, DALL-E’s training data and output feature more images of men than women.
This technical issue is both well known and well studied, even if the people who build algorithms have not yet solved it. Meanwhile, scholars and advocates across a wide variety of disciplines have also examined other types of algorithmically-generated content whose developers obtained training data from public sources—such as social media—without the owners’ permission.
“Think of Google returning and ranking search results, Google translation, and all of the algorithms that are figuring out what ads to serve us,” Janelle Shane, an optics researcher and author of the book You Look Like a Thing and I Love You (about the pitfalls of machine learning), said [1]. “A lot of those algorithms are based on writers’ data, bloggers’ data, or emailers’ data — a bunch of people who did not agree to have their data as part of these datasets.”
Shane’s work in this area has frequently focused on the weird and unexpected results that stem from AI systems, including DALL-E. She noted that most of the output from these algorithms is not usable as-is—except perhaps humorously—which means that human artists must post-process the results via image manipulation programs like Photoshop. While this situation will probably change as algorithms improve, much of what is currently displayed as “AI art” is not purely computer generated.
The Laws and the Profits
In sharing their different perspectives, Rose, Shane, and Williams all highlighted the need to examine training data for AI art through an ethical lens — allowing ethics to guide both the technical and legal aspects of the situation. This logic applies even more so in the context of photographs, especially since DALL-E 2 just permitted their use as training data in September 2022. This decision spurred worries about the creation of deepfake photos, wherein a person’s face or body is digitally included in unrelated images for the purposes of defamation.
“If you’re using someone’s photographs without their permission or knowledge, then you shouldn’t be using those photographs,” Williams said. He referenced the case of Clearview AI, the company that collected photos from the internet—without permission from photographers or subjects—to train its facial recognition algorithms, then sold its databases to law enforcement and military agencies.
Both Williams and Shane emphasized the responsibilities of the algorithm programmers, who decide what training data to incorporate and how the AIs will use it. Williams suggested that algorithms should be required to catalog the provenance of all of their training data in some capacity, much like how museum catalogs track the history of the art that they display. Ideally, such a stipulation would also allow artists to determine whether their work has been utilized without their permission. “The responsibility lies primarily with the individuals, the teams, and the corporations building these algorithms,” Williams said.
Shane added that current AI art programs draw indiscriminately on huge datasets, which does not have to be the case. “Probably the solution is [to say] ‘Hey, we should build our algorithms with less, so we don’t have to scrape everything we can get our hands on,’” she said. “We can train with a cleaner, more controlled, more consented dataset. That also has the advantage of starting to address some of the biases inherent in a dataset that you scrape from all of the art propagated on the internet, on museum websites, and so forth.”
Copyright law is not currently designed to treat large training datasets that contain protected works. But other types of law might be relevant, such as those that prohibit “revenge porn.” Many art-hosting websites have already begun to ban AI-generated art, partly because users can flood their servers and prevent non-algorithmic artists from getting any visibility. As the appearance of AI art continues to improve—as it inevitably will—human creators, users, and lawmakers must think of ways to enhance the ethics of AI art before the harm overwhelms the fun.
1 For the sake of simplicity, I use the term “artificial intelligence” to encompass machine learning and algorithmically generated content, in accordance with colloquial practice.
Further Reading
[1] Shane, J. (2019). You look like a thing and I love you: How artificial intelligence works and why it’s making the world a weirder place. New York, NY: Voracious/Little, Brown and Company.
About the Author
Matthew R. Francis
Science writer
Matthew R. Francis is a physicist, science writer, public speaker, educator, and frequent wearer of jaunty hats. His website is https://bowlerhatscience.org.
Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
