
The Impact of Data-driven Digital Twins on Healthcare and Environmental Sustainability
Digital twins are revolutionizing various fields within science and engineering, from the testing of novel materials to the detection of early disease signatures and assessment of global soil health. By leveraging advanced data analytics and machine learning, digital twins enable real-time monitoring and predictive capabilities that can significantly improve decision-making processes. Here, we explore several compelling applications of digital twins, including the early detection of infectious diseases, evaluation of soil organic carbon (SOC) for environmental sustainability, and appraisal of novel material compatibility.
Early Detection of Infectious Diseases Via Wearable Data
The early detection of potential infectious disease outbreaks is crucial for effective public health interventions. Wearable devices—such as smartwatches—offer a promising avenue for early outbreak detection by continuously monitoring health parameters of individuals and populations. These uninterrupted observations facilitate the early identification of potential disease outbreaks based on deviations from baseline physiology, which may indicate the beginning of an infection.
We integrate Wasserstein generative adversarial networks (WGANs) with data streaming and higher-order anomaly detection to provide a new perspective on healthcare data analysis while simultaneously addressing privacy concerns (see Figure 1). This novel combination enhances the method’s effectiveness and applicability across multiple scientific and technological domains.
We utilized real-world wearable sensor time series data from devices like Fitbit and Apple Watch, based on published studies. Our dataset includes activity data (e.g., step count and sleep patterns) and vital health information (e.g., heart rate) for 119 representative users, collected every 60 seconds; 44 of these users self-reported as having respiratory infections (COVID-19, influenza, etc.). By setting personalized thresholds for resting heart rate and employing the Hellinger distance, our anomaly detection method successfully raised pre-symptomatic warnings for 41 (93 percent) of the sick users — significantly outperforming prior studies [1, 7].
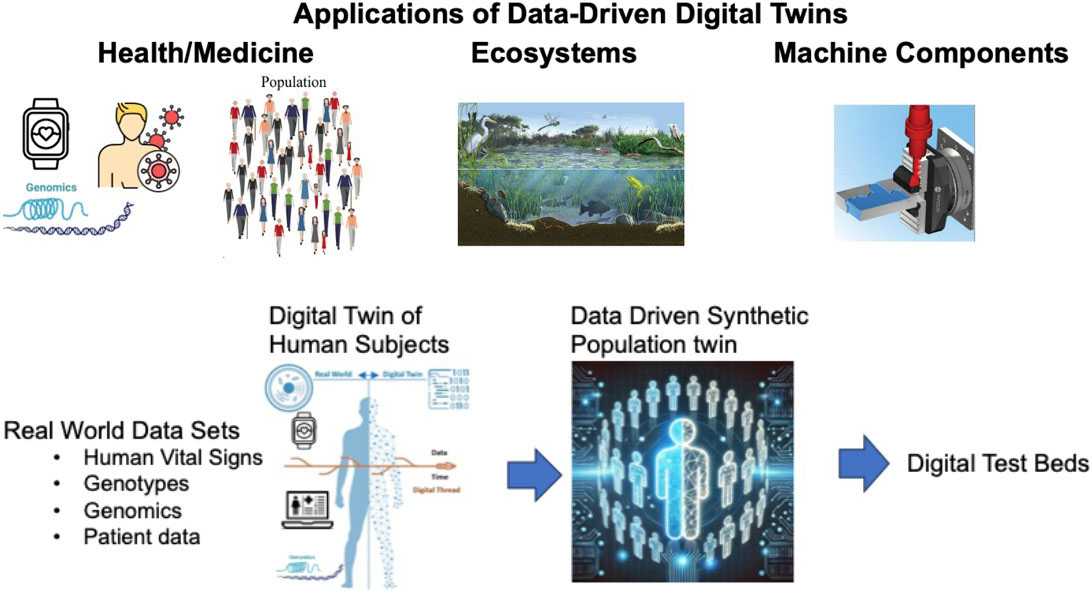
However, we cannot rely solely on a limited amount of real user data when developing effective algorithms for anomaly detection at the population level. The scarcity of personalized health data—often constrained by factors such as cost and privacy concerns—poses significant challenges. For machine learning models to make informed observations, they must have access to a sufficient quantity and quality of data.
In this context, synthetic data generation emerges as a viable solution. By using generative artificial intelligence (GenAI) to create realistic synthetic data, we can train machine learning models on larger and more diverse datasets to ultimately yield increasingly robust decision-making capabilities. Generating, verifying, and validating digital twins—as well as augmenting data—are all critical aspects of this work. Our technique hence serves as a prototype that is applicable to real datasets, particularly during any infectious disease outbreak.
We can also employ this concept to predict the onset of disease based on patients’ biochemistry data (medical history, blood work, symptoms, genomics, microbiome characterization, etc.). In particular, we use integrative human microbiome data to train an explainable predictive machine learning model for disease forecasting, which can then serve as a digital twin to predict disease types and possible causes of dysbiosis (i.e., change in microbe composition). We are currently using this strategy to study viral infectious disease models; although we are in the early stages of research, we believe that our approach has significant potential to impact the future of precision medicine.
Data Augmentation for Soil Organic Carbon
Soil health is directly linked to food security and global ecosystem dynamics [9, 10]. Despite significant efforts to collect soil profile data, many regions—such as the northern circumpolar region [3]—still suffer from low sample density, especially in areas with known uncertainties in changing environmental conditions.
Permafrost-region soils, which are characterized by ground temperatures that remain at or below 0° Celsius for extended periods, are critical SOC reservoirs (see Figure 2). Because these unique, cold, water-saturated environments slow decomposition rates, we must understand SOC dynamics in high-latitude ecosystems to reliably estimate carbon stocks. This knowledge can inform ecological and geological studies while addressing the challenges of data scarcity.
To tackle this issue, we developed a domain-specific framework for synthetic data generation that enhances our understanding of soil carbon distribution. We employ a data curation module to filter and cluster input data based on key environmental factors, which allows us to generate synthetic data—via a GenAI module—that follow the statistical signature of real data.
We utilize GenAI-based WGANs to generate digital twins of unknown datasets that replicate the characteristics of SOC measurements, even in regions with sparse data [2, 4, 6]. Our methodology includes a site-level k-fold cross-validation method to ensure the synthetic data’s accuracy, thus enhancing the reliability of spatial predictions. By integrating environmental predictors like mean annual temperature and precipitation, the framework refines the synthetic data generation process and supports tailored applications in soil health assessment.
![<strong>Figure 2.</strong> Schematic of the data augmentation workflow and its validation. The “Data collection” panel depicts site locations of soil organic carbon observations in permafrost regions. Figure courtesy of the authors; “Data collection” panel adapted from [8].](/media/hxkhkaoz/figure2.jpg)
Material Component Digital Twins for Digital Characterization
Additionally, our team has developed several machine learning models to predict material properties [5]; we have also retrained transformer generative models like MolGPT for material discovery and characterization. By using the known requirements of desired material components, our strategy creates a digital twin of components for in silico material compatibility testing. This approach reduces the burden of experimental validation for mission-critical materials and accelerates material discovery.
Conclusions
The many applications of digital twins in science and engineering highlight their transformative potential to tackle important societal challenges. By harnessing the power of advanced data analytics and machine learning, digital twins can provide timely insights that enhance decision-making processes and improve outcomes across various fields. Their potential extends well beyond research, as digital twins can play a crucial role in improving public health, enhancing environmental sustainability, and driving innovation. As we continue this work, the integration of synthetic data generation and real-world data will yield robust models that can effectively respond to emerging health, engineering, and environmental threats.
Ultimately, the continuous innovation in digital twin technology is crucial for the future of science and engineering. By embracing these advancements, we can better address the pressing challenges of our time.
This article is based on a two-part minisymposium session that was organized by Uma Balakrishnan and Kunal Poorey at the 2025 SIAM Conference on Computational Science and Engineering, which took place in Fort Worth, Texas, earlier this year.
References
[1] Alavi, A., Bogu, G., Wang, M., Rangan, E.S., Brooks, A.W., Wang, Q., … Snyder, M.P. (2022). Real-time alerting system for COVID-19 and other stress events using wearable data. Nat. Med., 28(1), 175-184.
[2] Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In Proceedings of the 34th international conference on machine learning (pp. 214-223). Sydney, Australia: Journal of Machine Learning Research.
[3] Batjes, N.H., Calisto, L., & de Sousa, L.M. (2024). Providing quality-assessed and standardised soil data to support global mapping and modelling (WoSIS snapshot 2023). Earth Syst. Sci. Data, 16(10), 4735-4765.
[4] Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. (2017). Improved training of Wasserstein GANs. In NIPS’17: Proceedings of the 31st international conference on neural information processing systems (pp. 5769-5779). Long Beach, CA: Curran Associates Inc.
[5] Kamruzzaman, M., Landera, A., Menon, N.C, Allendorf, M.D., & Poorey, K. (2024). P2MAT: A machine learning (ML) driven software for Property Prediction of MATerial. Preprint, ChemRxiv.
[6] Kamruzzaman, M., Salinas, J., Kolla, H., Sale, K., Balakrishnan, U., & Poorey, K. (2024). GenAI based digital twins aided data augmentation increases accuracy in real-time cokurtosis based anomaly detection of wearable data. Preprint, Research Square.
[7] Mishra, T., Wang, M., Metwally, A.A., Bogu, G.K., Brooks, A.W., Bahmani, A., … Snyder, M.P. (2020). Pre-symptomatic detection of COVID-19 from smartwatch data. Nat. Biomed. Eng., 4, 1208-1220.
[8] Mishra, U., Gautam, S., Riley, W.J., & Hoffman, F.M. (2020). Ensemble machine learning approach improves predicted spatial variation of surface soil organic carbon stocks in data-limited northern circumpolar region. Front. Big Data, 3, 528441.
[9] Mishra, U., Yeo, K, Adhikari, K., Riley, W.J., Hoffman, F.M., Hudson, C., & Gautam, S. (2022). Empirical relationships between environmental factors and soil organic carbon produce comparable prediction accuracy to machine learning. Soil Sci. Soc. Am. J., 86(6), 1611-1624.
[10] Stockmann, U., Padarian, J., McBratney, A., Minasny, B., de Brogniez, D., Montanarella, L., … Field, D.J. (2015). Global soil organic carbon assessment. Glob. Food Secur., 6, 9-16.
About the Authors
Uma Balakrishnan
Scientist, Sandia National Laboratories
Uma Balakrishnan is a scientist in the Quantitative Modeling & Software Engineering Department at Sandia National Laboratories. Her research focuses on computational fluid dynamics, scientific machine learning, verification, validation and uncertainty quantification, generative artificial intelligence and data-driven digital twins in turbulence modeling, biosciences, and Earth sciences.

Kunal Poorey
Staff scientist, Sandia National Laboratories
Kunal Poorey is a staff scientist in the Systems Biology Department at Sandia National Laboratories. His work in applied data science finds various applications in engineering and bioscience, including novel research in artificial intelligence, biology, chemistry, and materials science.

Jorge Salinas
Postdoctoral fellow, Sandia National Laboratories
Jorge Salinas is a postdoctoral fellow at Sandia National Laboratories. His research focuses on computational fluid dynamics for combustion flows and generative artificial intelligence in the biosciences and Earth sciences.

Md Kamruzzaman
Postdoctoral researcher, Sandia National Laboratories
Md (Methun) Kamruzzaman is a postdoctoral researcher at Sandia National Laboratories. His work focuses on generative artificial intelligence (AI) to synthesize digital twins in health informatics, large language models in cheminformatics, bioinformatics, and materials science. He is passionate about the use of advanced AI and machine learning in the context of cross-domain challenges.

Related Reading
Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
