
Using Differential Privacy to Protect the United States Census
In 2006, Netflix hosted a competition to improve its algorithm for providing movie recommendations to customers based on their past choices. The DVD rental and video streaming service shared anonymized rental records from real subscribers, assuming that their efforts to remove identifying information sufficiently protected user identities. This assumption was wrong; external researchers quickly proved that they could pinpoint personal details by correlating other public data with the Netflix database, potentially exposing private information.
This fatal flaw in the Netflix Prize challenge highlights multiple issues concerning privacy in the information age, including the simultaneous need to perform statistical analyses while protecting the identities of people in the dataset. Merely hiding personal data is not enough, so many statisticians are turning to differential privacy. This method allows researchers to extract useful aggregate information from data while preserving the privacy of individuals within the sample.
“Even though researchers are just trying to learn facts about the world, their analyses might incidentally reveal sensitive information about particular people in their datasets,” Aaron Roth, a statistician at the University of Pennsylvania, said. “Differential privacy is a mathematical constraint you impose on an algorithm for performing data analysis that provides a formal guarantee of privacy.”
Differential privacy protects individuals in a dataset from identification by injecting noise into the data. This yields a probability distribution, from which it is nearly impossible—in a practical sense—to determine a particular record’s presence within the set. In other words, anyone performing statistical analysis will not be able to link a specific person to their details contained in the database.
Such protections are more than simply good ideas. The U.S. Census Bureau is legally obligated to guard the privacy of the people it surveys for civil rights reasons, including voting protections. To that end, the 2020 U.S. Census will implement differential privacy, marking a major shift in how the U.S. government handles information propagation.
John Abowd, chief scientist and associate director for research and methodology at the U.S. Census Bureau, spearheaded this change. During his presentation at the American Association for the Advancement of Science 2019 Annual Meeting, which took place earlier this year in Washington, D.C., Abowd highlighted the current inadequacies of privacy measures implemented during the 1990 Census.
“We don’t have the option of saying that it’s broken and we can’t fix it, so we’ll keep using it,” Abowd said. “So we searched for a technology that could provably address this vulnerability. And there’s exactly one: differential privacy.”
From Flipping Coins to Noise Injection
To understand the philosophy behind the differential privacy paradigm, Roth proposes two nearly-identical worlds. “The same data analysis is run in both worlds,” he said. “But while your data is included in the analysis in one world, it is not in the other. There should be no statistical test that can reliably distinguish these two worlds better than random guessing. So that’s a strong guarantee of privacy: I can learn things about the population generally but I cannot learn anything about you because I cannot even tell whether I had access to your data.”
A simple version of differential privacy is a technique called “randomized response.” Consider a yes or no question that reveals embarrassing or illegal activity, e.g., “Have you used drugs in the past month?” Before answering, flip a coin; if it turns up tails, answer the question truthfully. If it lands on heads, flip a second coin and record a “yes” upon a second heads and a “no” upon tails, regardless of the true answer. Numerically, if your real answer is “yes,” the algorithm assigns a “yes” response to you roughly three-quarters of the time. The probable fraction \(f\) of “yes” answers in the randomized dataset is
\[f \simeq \frac{1}{4}(1+2p),\]
where \(p\) is the actual fraction of “yes” answers, and the estimate’s accuracy increases with the number of survey participants. Analysis of the resulting data ideally estimates the rate of the activity in question without exposing individuals to retaliation for truthful responses [1].
Differential privacy extends this concept to more complex datasets. Researchers determine the level of privacy they require, which is often sufficiently quantified by a single parameter \(\varepsilon\). Formally speaking, consider two datasets \(\{D, D'\}\) that differ by a small amount (one record in the basic case). An algorithm \(M\) is \(\varepsilon\)-differentially private if the probability \(P\) of extracting particular data \(x\) from both databases obeys the following inequality:
\[P\:[\!M(D) = x] \le \textrm{exp}(\varepsilon) P\:[\!M(D') = x].\]
This simple randomized response example is “\(\ln\) \(3\)-differentially private” because obtaining a truthful “yes” answer is three times more probable than getting a false “yes” answer: \(\varepsilon = \ln3\). More sophisticated privacy algorithms inject noise into data generated with the Laplace distribution \[\textrm{Lap} (x | b) = \frac{1}{2b}\textrm{exp}(-\frac{|x|}{b}),\] where \(b \propto 1/\varepsilon\) determines the scale of the distribution from which random values are drawn. The privacy guarantee is meaningless for large \(\varepsilon\) values because \(D\) and \(D'\) are too different, but small nonzero \(\varepsilon\) values can provide very strong privacy guarantees.
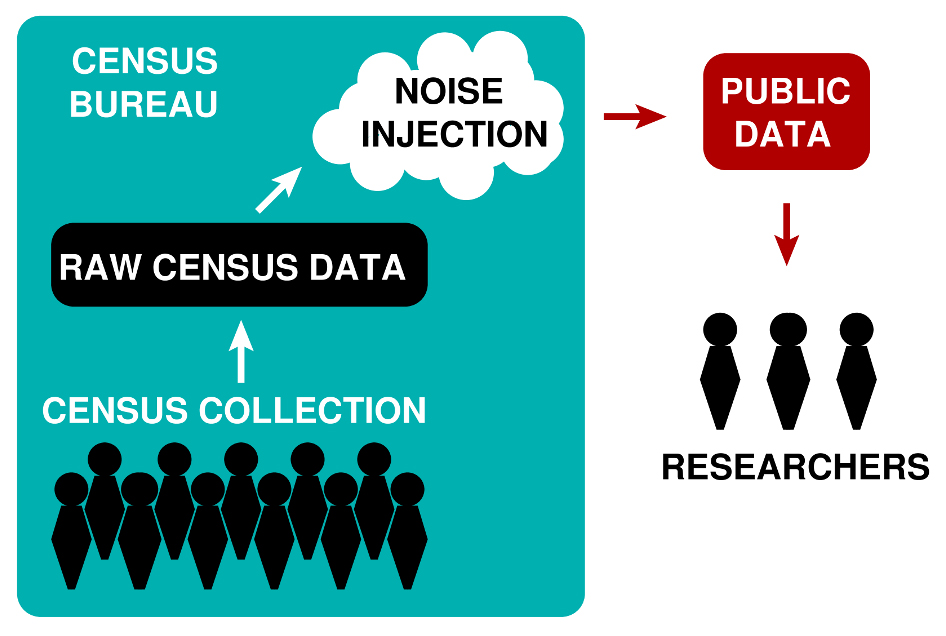
With regard to the census, it is essential that individuals not be linked to their geospatial location for a number of legal and ethical reasons. The differential privacy algorithm tested on past census datasets injects noise on multiple levels of the geographic hierarchy used in census tabulation (see Figure 1). “Oftentimes, people who use data are initially taken aback when we say we’re going to introduce noise into their data,” Roth said. “But it is important to remember that data is already noisy due to sampling error. The goal of differential privacy is to introduce just a bit more error, enough to hide with statistical uncertainty the influence that single data points have on any statistic we are releasing.”
He points out that a type of noise was already added to census data from 1990, 2000, and 2010. However, external analysts did not know the nature of that noise, which required them to either pretend that they had the raw data or make assumptions about the algorithm. “If you want to construct statistically valid confidence intervals around statistics computed from the data, you need to understand the process by which any noise was introduced,” Roth noted. “The guarantees of differential privacy are such that the mechanism that adds these perturbations can be made public. We are not getting any privacy guarantees from trying to keep things secret, and that’s a benefit for science.”
Future-proofing Privacy
Demographic data is people. Protecting the privacy of these people is at odds with sharing their data for research purposes, so privacy protections often involve “security through obscurity.” This is accomplished by hiding certain database fields from users—as with the Netflix Prize contest—or randomizing fields using a non-public algorithm, as the U.S. Census Bureau did with data from the previous three censuses.
However, when Census Bureau researchers accounted for modern algorithms and computing power, they discovered the inadequacy of these measures. Like with Netflix, security through obscurity collapsed when other public data sources were combined with the last census. This discovery created a sense of urgency during preparation for the 2020 Census.
“The system that was used to protect the 2010 Census [is] clearly no longer best practice,” Abowd said. “It does not provide protection against vulnerabilities that have emerged in the ensuing decade. The Census Bureau didn’t invent those vulnerabilities; they are an inevitable feature of the 21st-century information age.”
The protection afforded by differential privacy is sufficiently strong for Abowd to call it “future proof.” “The mathematical principle that underlies the risk measure used in differential privacy is a worst-case analysis,” he continued. “Once you apply the protections, you can release the data and never have to worry about a stronger attack undoing what you did because you have basically allowed for the strongest possible attack. If the worst case happens, the protection is even stronger than \(\varepsilon\).”
Differential privacy is not a magic guarantee of protection, and no algorithm can prevent compromise if a database contains enough identifying information to render noise injection worthless. Additionally, differential privacy cannot counter political manipulation. Census Bureau experts raised concerns over U.S. Secretary of Commerce Wilbur Ross’s recent proposal to add a citizenship question to the 2020 Census; they feared that people from vulnerable populations would opt out of responding, which would damage the data’s quality independent of privacy concerns [2].
Nevertheless, differential privacy may offer the best possible option for balancing openness, analytic usefulness, and privacy protections for individuals in the U.S. Census and other realistic datasets.
References
[1] Dwork, C., & Ross, A. (2014). The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci., 9(3-4), 211-407.
[2] Mervis, J. (2019). Can a set of equations keep U.S. census data private? Science. doi:10.1126/science.aaw5470.
About the Author
Matthew R. Francis
Science writer
Matthew R. Francis is a physicist, science writer, public speaker, educator, and frequent wearer of jaunty hats. His website is https://bowlerhatscience.org.
Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
